Entries tagged [jbatch]
jberetweb, JBeret job repository viewer
TweetPosted on Friday Jan 02, 2015 at 01:01AM in jberetweb
What are JBeret and jberetweb?
JBeret is the out-of-the-box JSR352 JBatch implementation of the WildFly application server. It manages its statuses of jobs and steps in several types of data storage, like RDBMS, which is called repository. But it has no management console or even a standardized way to see it efficiently (I've been watching the repository through SQL!). So, I have created jberetweb as a small web application which shows the JDBC job repository of JBeret.
jberetweb can be obtained at GitHub.
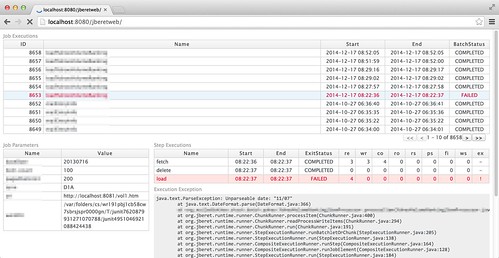
What can be done with jberetweb?
It shows recent job executions with their names, the start/end time and the batch status on the table in the upper half of the page. These rows are clickable. Additional information, like job parameters and step executions, will be shown when any row of the job executions table is clicked. Execution exception data will be shown if the step has failed because an exception occurred. Any problematic rows, such as a failed execution or step, are highlighted. Thanks to JSF's partial rendering and Ajax, paging and operations are fast.
How do I install it?
As I described at README.md in GitHub repository of it, you have to clone and build it with mvn yourself, and some configuration is needed for WildFly before deploying the WAR.
- Create a database on PostgreSQL (jberetweb should run on any other RDBMS, but I haven't tested yet)
- Register a XA data source for the job repository
- Register JNDI name of the JDBC job repository
- Set the job repository type as JDBC
- Define JSF project stage to JNDI
batch
xa-data-source add \
--name=JBatchDS \
--driver-name=postgresql \
--jndi-name=java:jboss/jdbc/JBatchDS \
--user-name=postgres \
--password=***
/subsystem=datasources/xa-data-source="JBatchDS"/xa-datasource-properties=ServerName:add(value="localhost")
/subsystem=datasources/xa-data-source="JBatchDS"/xa-datasource-properties=PortNumber:add(value="5432")
/subsystem=datasources/xa-data-source="JBatchDS"/xa-datasource-properties=DatabaseName:add(value="jbatch")
run-batch
/subsystem=batch/job-repository=jdbc:write-attribute(name=jndi-name, value=java:jboss/jdbc/JBatchDS)
/subsystem=batch:write-attribute(name=job-repository-type, value=jdbc)
/subsystem=naming/binding=java\:\/env\/jsf\/ProjectStage:add(binding-type=simple,value=Development,class=java.lang.String)
NOTE:
- JBeret creates the schema automatically if any tables aren't found, so make sure the database user can execute DDLs.
- Use XA datasource for both the job repository and your application database.
Here's some related pointers:
- [WFLY-3174] Add view of batch jobs with ability to view, restart and stop - JBoss Issue Tracker
- JSR 352 - Viewing batch jobs in admin console | JBoss Developer
I would be grateful for your feedback because it's my first software which is public on GitHub.
Chunk-oriented Processing with Hibernate's StatelessSession
TweetPosted on Tuesday Mar 11, 2014 at 08:24AM in Technology
- Bulk fetching is difficult with standard JPA API, but provider-specific functions make it easy.
- This is a example of such provider-specific bulk fetching function of Hibernate with JSR352.
According to JSR 352 Implementation - Connection close probl… | Community, this example seems to be wrong. every cursors need to be opened and closed in a transaction. so another approach is required, e.g. fetch primary keys in open(), then fetch each rows in readItem().
Environment
- WildFly8.0.0.Final
- Hibernate 4.3.1.Final
- Oracle JDK7u51
- PostgreSQL 9.2.4
Example
ItemReader
package org.nailedtothex.jbatch.example.chunk;
@Named
public class ChunkItemReader extends AbstractItemReader {
@PersistenceContext
EntityManager em;
ScrollableResults scroll;
StatelessSession ss;
Session session;
@Override
public void open(Serializable checkpoint) throws Exception {
session = em.unwrap(Session.class);
ss = session.getSessionFactory().openStatelessSession();
scroll = ss.createQuery("SELECT c FROM ChunkInputItem c ORDER BY c.id").scroll(ScrollMode.FORWARD_ONLY);
}
@Override
public Object readItem() throws Exception {
if (!scroll.next()) {
return null;
}
return scroll.get(0);
}
@Override
public void close() throws Exception {
try {
scroll.close();
} catch (Exception e) {
}
try {
ss.close();
} catch (Exception e) {
}
try {
session.close();
} catch (Exception e) {
}
}
}
- I'm not sure that close() procedures are mandatory or not.
ItemWriter
package org.nailedtothex.jbatch.example.chunk;
@Named
public class ChunkItemWriter extends AbstractItemWriter {
private static final Logger log = Logger.getLogger(ChunkItemWriter.class.getName());
@Override
public void writeItems(List<Object> items) throws Exception {
log.log(Level.FINE, "chunkItemWriter#writeItems(): {0}", new Object[] { items });
}
}
persistence.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="jbatchsls">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>java:jboss/jdbc/JBatchTestDS</jta-data-source>
<properties>
<property name="javax.persistence.schema-generation.database.action" value="none" />
<property name="hibernate.connection.release_mode" value="on_close"/>
</properties>
</persistence-unit>
</persistence>
- “hibernate.connection.release_mode” property is necessary.
- NOTE: use of this declaration is highly discouraged. see the additional note in the bottom of this article which explains the another way to realize it.
- If this is not set, then you will get:
15:24:59,047 INFO [org.hibernate.engine.jdbc.internal.JdbcCoordinatorImpl] (batch-batch - 19) HHH000106: Forcing container resource cleanup on transaction completion
15:24:59,048 WARN [org.hibernate.engine.jdbc.spi.SqlExceptionHelper] (batch-batch - 19) SQL Error: 0, SQLState: null
15:24:59,048 ERROR [org.hibernate.engine.jdbc.spi.SqlExceptionHelper] (batch-batch - 19) The result set is closed.
15:24:59,048 ERROR [org.jberet] (batch-batch - 19) JBERET000007: Failed to run job chunk, doChunk, org.jberet.job.model.Chunk@16d1364: org.hibernate.exception.GenericJDBCException: could not advance using next()
at org.hibernate.exception.internal.StandardSQLExceptionConverter.convert(StandardSQLExceptionConverter.java:54) [hibernate-core-4.3.1.Final.jar:4.3.1.Final]
at org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:126) [hibernate-core-4.3.1.Final.jar:4.3.1.Final]
at org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:112) [hibernate-core-4.3.1.Final.jar:4.3.1.Final]
at org.hibernate.internal.ScrollableResultsImpl.next(ScrollableResultsImpl.java:125) [hibernate-core-4.3.1.Final.jar:4.3.1.Final]
at org.nailedtothex.jbatch.example.chunk.ChunkItemReader.readItem(ChunkItemReader.java:31) [classes:]
at org.jberet.runtime.runner.ChunkRunner.readItem(ChunkRunner.java:343) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.ChunkRunner.readProcessWriteItems(ChunkRunner.java:288) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.ChunkRunner.run(ChunkRunner.java:190) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.StepExecutionRunner.runBatchletOrChunk(StepExecutionRunner.java:204) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.StepExecutionRunner.run(StepExecutionRunner.java:131) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.CompositeExecutionRunner.runStep(CompositeExecutionRunner.java:162) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.CompositeExecutionRunner.runFromHeadOrRestartPoint(CompositeExecutionRunner.java:88) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.JobExecutionRunner.run(JobExecutionRunner.java:58) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.wildfly.jberet.services.BatchEnvironmentService$WildFlyBatchEnvironment$1.run(BatchEnvironmentService.java:149) [wildfly-jberet-8.0.0.Final.jar:8.0.0.Final]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) [rt.jar:1.7.0_51]
at java.util.concurrent.FutureTask.run(FutureTask.java:262) [rt.jar:1.7.0_51]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) [rt.jar:1.7.0_51]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) [rt.jar:1.7.0_51]
at java.lang.Thread.run(Thread.java:744) [rt.jar:1.7.0_51]
at org.jboss.threads.JBossThread.run(JBossThread.java:122)
Caused by: java.sql.SQLException: The result set is closed.
at org.jboss.jca.adapters.jdbc.WrappedResultSet.checkState(WrappedResultSet.java:4081)
at org.jboss.jca.adapters.jdbc.WrappedResultSet.next(WrappedResultSet.java:1855)
at org.hibernate.internal.ScrollableResultsImpl.next(ScrollableResultsImpl.java:120) [hibernate-core-4.3.1.Final.jar:4.3.1.Final]
... 16 more
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>jbatchsls</groupId>
<artifactId>jbatchsls</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>war</packaging>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<failOnMissingWebXml>false</failOnMissingWebXml>
</properties>
<dependencies>
<dependency>
<groupId>org.nailedtothex</groupId>
<artifactId>jbatchif</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-api</artifactId>
<version>7.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>4.3.1.Final</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hamcrest</groupId>
<artifactId>hamcrest-core</artifactId>
<version>1.3</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jboss</groupId>
<artifactId>jboss-remote-naming</artifactId>
<version>2.0.0.Final</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jboss.xnio</groupId>
<artifactId>xnio-nio</artifactId>
<version>3.2.0.Final</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
ChunkInputItem
package org.nailedtothex.jbatch.example.chunk;
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class ChunkInputItem implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(nullable = false)
private Long id;
@Column
private Integer input;
@Column
private Boolean processed;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public Integer getInput() {
return input;
}
public void setInput(Integer input) {
this.input = input;
}
public Boolean getProcessed() {
return processed;
}
public void setProcessed(Boolean processed) {
this.processed = processed;
}
@Override
public String toString() {
return "ChunkInputItem [id=" + id + ", input=" + input + ", processed=" + processed + "]";
}
}
Test data
jbatcharts=# select * from chunkinputitem ; id | input | processed ----+-------+----------- 0 | 0 | f 1 | 10 | f 2 | 20 | f 3 | 30 | f 4 | 40 | f 5 | 50 | f 6 | 60 | f 7 | 70 | f 8 | 80 | f 9 | 90 | f (10 rows) jbatcharts=#
Log
15:29:03,916 DEBUG [org.hibernate.SQL] (batch-batch - 20) select chunkinput0_.id as id1_0_, chunkinput0_.input as input2_0_, chunkinput0_.processed as processe3_0_ from ChunkInputItem chunkinput0_ order by chunkinput0_.id 15:29:03,918 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 20) chunkItemWriter#writeItems(): [ChunkInputItem [id=0, input=0, processed=false], ChunkInputItem [id=1, input=10, processed=false], ChunkInputItem [id=2, input=20, processed=false]] 15:29:03,920 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 20) chunkItemWriter#writeItems(): [ChunkInputItem [id=3, input=30, processed=false], ChunkInputItem [id=4, input=40, processed=false], ChunkInputItem [id=5, input=50, processed=false]] 15:29:03,922 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 20) chunkItemWriter#writeItems(): [ChunkInputItem [id=6, input=60, processed=false], ChunkInputItem [id=7, input=70, processed=false], ChunkInputItem [id=8, input=80, processed=false]] 15:29:03,925 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 20) chunkItemWriter#writeItems(): [ChunkInputItem [id=9, input=90, processed=false]]
A way to avoid “hibernate.connection.release_mode=on_close”
- ItemReader like this works with no declaration of “hibernate.connection.release_mode=on_close” which highly discouraged[2].
public abstract class AbstractHibernateItemReader extends AbstractItemReader {
@PersistenceContext
EntityManager em;
@Resource
DataSource ds;
Connection cn;
ScrollableResults scroll;
StatelessSession ss;
Session session;
@Override
public void open(Serializable checkpoint) throws Exception {
cn = ds.getConnection();
cn.setHoldability(ResultSet.HOLD_CURSORS_OVER_COMMIT);
session = em.unwrap(Session.class);
ss = session.getSessionFactory().openStatelessSession(cn);
scroll = ss.createQuery("SELECT c FROM ChunkInputItem c ORDER BY c.id").scroll(ScrollMode.FORWARD_ONLY);
}
...
@Override
public void close() throws Exception {
try {
scroll.close();
} catch (Exception e) {
}
try {
ss.close();
} catch (Exception e) {
}
try {
session.close();
} catch (Exception e) {
}
try {
cn.close();
} catch (Exception e) {
}
}
...
- Ugly but I guess that it would be better for some occasions.
- There's no proper way to set holdability of resultset with StatelessSession[3].
- Configure through Session#doWork() and SessionImpl#connection() didn't worked as expectedly.
- Both of them brings “The result set is closed”.
References
Tags: jbatch
Job testing with remote EJB invocation
TweetPosted on Wednesday Feb 26, 2014 at 04:50PM in Technology
I introduced that a way to test a JSR352 job with Arquillian, but I guess it's might too complex for testing of a JSR352 job, so I'm going to try to test them without Arquillian.
Environment
- WildFly 8.0.0.Final
- Oracle JDK7u51
Sample project
- Whole resources are available at GitHub.
- Example test class is HelloJobTest.
How does it work?
- JUnit test class lookups javax.batch.operations.JobOperator instance from Remote WildFly through Remote EJB Interface.
- Test class kicks the job.
- Test class will wait till the job finished.
- Assert BatchStatus.
How do I run on other application servers?
- I don't know surely, but edit below resources may helps:
- jndi.properties
- AbstractJobTest.java (JNDI_NAME)
- Also appropriate jar files for remote EJB invocation are required.
Log of WildFly
17:06:18,214 INFO [stdout] (batch-batch - 3) hello
Local log
2 26, 2014 5:14:39 午後 org.xnio.Xnio <clinit>
INFO: XNIO version 3.2.0.Final
2 26, 2014 5:14:40 午後 org.xnio.nio.NioXnio <clinit>
INFO: XNIO NIO Implementation Version 3.2.0.Final
2 26, 2014 5:14:40 午後 org.jboss.remoting3.EndpointImpl <clinit>
INFO: JBoss Remoting version 4.0.0.Final
2 26, 2014 5:14:40 午後 org.jboss.ejb.client.remoting.VersionReceiver handleMessage
INFO: EJBCLIENT000017: Received server version 2 and marshalling strategies [river]
2 26, 2014 5:14:40 午後 org.jboss.ejb.client.remoting.RemotingConnectionEJBReceiver associate
INFO: EJBCLIENT000013: Successful version handshake completed for receiver context EJBReceiverContext{clientContext=org.jboss.ejb.client.EJBClientContext@2db9e6d7, receiver=Remoting connection EJB receiver [connection=org.jboss.ejb.client.remoting.ConnectionPool$PooledConnection@7e244b5,channel=jboss.ejb,nodename=kyle-no-macbook]} on channel Channel ID c584a9f3 (outbound) of Remoting connection 09168b43 to localhost/127.0.0.1:8080
2 26, 2014 5:14:40 午後 org.jboss.ejb.client.EJBClient <clinit>
INFO: JBoss EJB Client version 2.0.0.Final
Remarks
- It's much faster than Arquillian Remoting on my environment.
Tags: jbatch
Job-wide artifact injection with CDI Producer
TweetPosted on Tuesday Feb 25, 2014 at 05:37PM in Technology
Environment
- jBeret 1.0.1Beta-SNAPSHOT
- WildFly 8.0.0.Final
Why need it?
- Logger injection through CDI is easy and useful, but for jBatch programming of some occasions, I guess that Job-wide Logger is better than typical class-wide logger. thus, I will try it this time.
- With CDI, we can reduce some annoying code, even related to Job Properties so I also will try to inject a job-level property to a Batchlet through Producer.
Sample project
- jBatch resources
- CDI resources
- Test class
How does it work?
- 2 Injections are declared in InjectBatchlet.
- Both of them will be produced by JobWideArtifactProducer.
- JobWideArtifactProducer creates:
- a logger. the name contains job name.
- a Date. it came from job-level property named “baseDate”.
Log
18:14:51,064 INFO [job.jobwideproducer] (batch-batch - 3) process(): baseDate=14/02/25 0:00
Remarks
- Injection of variables such as working directory of the job may be useful too.
References
Tags: jbatch
ExitStatusでフロー制御してみる
TweetPosted on Sunday Feb 16, 2014 at 08:17AM in Technology
ExitStatusでフロー制御的なことをして遊んでみる
環境・前提条件
- Chunk方式のStepで例外発生時にスキップさせてみると同じ。ここで作ったプロジェクトが普通に動いているものとする
仕様を見てみる
[1]から引いてみる
8.6 Transition Elements
Transition elements may be specified in the containment scope of a step, flow, split, or decision to direct job execution sequence or to terminate job execution. There are four transition elements:
- next - directs execution flow to the next execution element.
- fail - causes a job to end with FAILED batch status.
- end - causes a job to end with COMPLETED batch status.
- stop - causes a job to end with STOPPED batch status.
Fail end, and stop are considered “terminating elements” because they cause a job execution to terminate.
この4つを使って遊んでみる
サンプルの仕様
- 第一レベルの要素は以下
- step1
- step2
- どちらも参照するartifactは同じExitStatusBatchlet
- パラメータで与えたExitStatusで終わるだけ
- step1のExitStatusはジョブパラメータで変えられるようにしてある
- step2のExitStatusはnull(COMPLETED)固定
- step1には先で引いたTransition Elementsを4つ指定してある
- 4つのテストメソッドでstep1のExitStatusを以下のパターンで変えてテストする
- next(): step2に遷移する
- fail(): step1で異常終了
- end(): step1で正常終了
- stop(): step1で停止
資源
資源はこのへんにまとめて全部ある
動かしてみる
next
ログ
10:29:46,990 FINE [org.nailedtothex.jbatch.example.on.ExitStatusBatchlet] (batch-batch - 6) step1: exitStatus=NEXT 10:29:47,009 FINE [org.nailedtothex.jbatch.example.on.ExitStatusBatchlet] (batch-batch - 6) step2: exitStatus=null
Repository
job_execution
jbatch=# select * from job_execution order by jobexecutionid desc limit 1;
jobexecutionid | jobinstanceid | version | createtime | starttime | endtime | lastupdatedtime | batchstatus | exitstatus | jobparameters | restartposition
----------------+---------------+---------+-------------------------+-------------------------+-------------------------+-------------------------+-------------+------------+-------------------+-----------------
148 | 141 | | 2014-02-16 10:29:46.976 | 2014-02-16 10:29:46.976 | 2014-02-16 10:29:47.011 | 2014-02-16 10:29:47.011 | COMPLETED | COMPLETED | exitStatus = NEXT+|
| | | | | | | | | |
(1 row)
step_execution
jbatch=# select * from step_execution where jobexecutionid in (148) order by jobexecutionid, stepexecutionid;
stepexecutionid | jobexecutionid | version | stepname | starttime | endtime | batchstatus | exitstatus | executionexception | persistentuserdata | readcount | writecount | commitcount | rollbackcount | readskipcount | processskipcount | filtercount | writeskipcount | readercheckpointinfo | writercheckpointinfo
-----------------+----------------+---------+----------+-------------------------+-------------------------+-------------+------------+--------------------+--------------------+-----------+------------+-------------+---------------+---------------+------------------+-------------+----------------+----------------------+----------------------
171 | 148 | | step1 | 2014-02-16 10:29:46.982 | 2014-02-16 10:29:46.991 | COMPLETED | NEXT | | | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
172 | 148 | | step2 | 2014-02-16 10:29:47.008 | 2014-02-16 10:29:47.009 | COMPLETED | COMPLETED | | | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
(2 rows)
- 普通にstep2に遷移している
fail
ログ
10:41:31,341 FINE [org.nailedtothex.jbatch.example.on.ExitStatusBatchlet] (batch-batch - 9) step1: exitStatus=FAIL
Repository
job_execution
jbatch=# select * from job_execution order by jobexecutionid desc limit 1;
jobexecutionid | jobinstanceid | version | createtime | starttime | endtime | lastupdatedtime | batchstatus | exitstatus | jobparameters | restartposition
----------------+---------------+---------+-------------------------+-------------------------+-------------------------+-------------------------+-------------+---------------------------+-------------------+-----------------
149 | 142 | | 2014-02-16 10:41:31.338 | 2014-02-16 10:41:31.338 | 2014-02-16 10:41:31.344 | 2014-02-16 10:41:31.344 | FAILED | EARLY COMPLETION (FAILED) | exitStatus = FAIL+|
| | | | | | | | | |
(1 row)
step_execution
jbatch=# select * from step_execution where jobexecutionid in (149) order by jobexecutionid, stepexecutionid;
stepexecutionid | jobexecutionid | version | stepname | starttime | endtime | batchstatus | exitstatus | executionexception | persistentuserdata | readcount | writecount | commitcount | rollbackcount | readskipcount | processskipcount | filtercount | writeskipcount | readercheckpointinfo | writercheckpointinfo
-----------------+----------------+---------+----------+-------------------------+-------------------------+-------------+------------+--------------------+--------------------+-----------+------------+-------------+---------------+---------------+------------------+-------------+----------------+----------------------+----------------------
173 | 149 | | step1 | 2014-02-16 10:41:31.339 | 2014-02-16 10:41:31.341 | COMPLETED | FAIL | | | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
(1 row)
- step1終了後に異常終了している
- step_executionのbatchstatusがCOMPLETEDなのが気になるけどjob_executionのbatchstatusはちゃんとFAILEDになっている
end
ログ
10:43:54,134 FINE [org.nailedtothex.jbatch.example.on.ExitStatusBatchlet] (batch-batch - 3) step1: exitStatus=END
Repository
job_execution
jbatch=# select * from job_execution order by jobexecutionid desc limit 1;
jobexecutionid | jobinstanceid | version | createtime | starttime | endtime | lastupdatedtime | batchstatus | exitstatus | jobparameters | restartposition
----------------+---------------+---------+-------------------------+-------------------------+-------------------------+-------------------------+-------------+------------------------+------------------+-----------------
150 | 143 | | 2014-02-16 10:43:54.129 | 2014-02-16 10:43:54.129 | 2014-02-16 10:43:54.137 | 2014-02-16 10:43:54.137 | COMPLETED | EARLY COMPLETION (END) | exitStatus = END+|
| | | | | | | | | |
(1 row)
step_execution
jbatch=# select * from step_execution where jobexecutionid in (150) order by jobexecutionid, stepexecutionid;
stepexecutionid | jobexecutionid | version | stepname | starttime | endtime | batchstatus | exitstatus | executionexception | persistentuserdata | readcount | writecount | commitcount | rollbackcount | readskipcount | processskipcount | filtercount | writeskipcount | readercheckpointinfo | writercheckpointinfo
-----------------+----------------+---------+----------+------------------------+-------------------------+-------------+------------+--------------------+--------------------+-----------+------------+-------------+---------------+---------------+------------------+-------------+----------------+----------------------+----------------------
174 | 150 | | step1 | 2014-02-16 10:43:54.13 | 2014-02-16 10:43:54.134 | COMPLETED | END | | | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
(1 row)
- step2には遷移せず正常終了している
stop
ログ
10:46:52,718 FINE [org.nailedtothex.jbatch.example.on.ExitStatusBatchlet] (batch-batch - 2) step1: exitStatus=STOP
Repository
job_execution
jbatch=# select * from job_execution order by jobexecutionid desc limit 1;
jobexecutionid | jobinstanceid | version | createtime | starttime | endtime | lastupdatedtime | batchstatus | exitstatus | jobparameters | restartposition
----------------+---------------+---------+-------------------------+-------------------------+------------------------+------------------------+-------------+-------------------------+-------------------+-----------------
151 | 144 | | 2014-02-16 10:46:52.705 | 2014-02-16 10:46:52.705 | 2014-02-16 10:46:52.72 | 2014-02-16 10:46:52.72 | STOPPED | EARLY COMPLETION (STOP) | exitStatus = STOP+| step2
| | | | | | | | | |
(1 row)
step_execution
jbatch=# select * from step_execution where jobexecutionid in (151) order by jobexecutionid, stepexecutionid;
stepexecutionid | jobexecutionid | version | stepname | starttime | endtime | batchstatus | exitstatus | executionexception | persistentuserdata | readcount | writecount | commitcount | rollbackcount | readskipcount | processskipcount | filtercount | writeskipcount | readercheckpointinfo | writercheckpointinfo
-----------------+----------------+---------+----------+-------------------------+-------------------------+-------------+------------+--------------------+--------------------+-----------+------------+-------------+---------------+---------------+------------------+-------------+----------------+----------------------+----------------------
175 | 151 | | step1 | 2014-02-16 10:46:52.712 | 2014-02-16 10:46:52.718 | COMPLETED | STOP | | | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
(1 row)
- step1終了後に停止している
- step_executionのbatchstatusがCOMPLETEDなのが気になるけどjob_executionのbatchstatusはちゃんとSTOPPEDになっている
stop要素のrestart属性で再実行時に遷移するstepを指定してみる
仕様を引いてみる
[1]の「8.6.4 Stop Element」に、restart属性についてこう書いてある
Specifies the job-level step, flow, or split at which to restart when the job is restarted. It must be a valid XML string value. This is a required attribute.
再実行してみる
テストメソッドstopRestart()に再実行のテストを書いてあるので実行してみる
ログ
10:58:59,039 FINE [org.nailedtothex.jbatch.example.on.ExitStatusBatchlet] (batch-batch - 4) step1: exitStatus=STOP 10:59:00,053 WARN [org.jberet] (batch-batch - 6) JBERET000018: Could not find the original step execution to restart. Current step execution id: 0, step name: step2 10:59:00,054 FINE [org.nailedtothex.jbatch.example.on.ExitStatusBatchlet] (batch-batch - 6) step2: exitStatus=null
Repository
job_execution
jbatch=# select * from job_execution where jobexecutionid in (161, 162) order by jobexecutionid;
jobexecutionid | jobinstanceid | version | createtime | starttime | endtime | lastupdatedtime | batchstatus | exitstatus | jobparameters | restartposition
----------------+---------------+---------+-------------------------+-------------------------+-------------------------+-------------------------+-------------+-------------------------+-------------------+-----------------
161 | 151 | | 2014-02-16 10:58:59.035 | 2014-02-16 10:58:59.035 | 2014-02-16 10:58:59.042 | 2014-02-16 10:58:59.042 | STOPPED | EARLY COMPLETION (STOP) | exitStatus = STOP+| step2
| | | | | | | | | |
162 | 151 | | 2014-02-16 10:59:00.05 | 2014-02-16 10:59:00.05 | 2014-02-16 10:59:00.056 | 2014-02-16 10:59:00.056 | COMPLETED | COMPLETED | exitStatus = STOP+|
| | | | | | | | | |
(2 rows)
step_execution
jbatch=# select * from step_execution where jobexecutionid in (161, 162) order by jobexecutionid, stepexecutionid;
stepexecutionid | jobexecutionid | version | stepname | starttime | endtime | batchstatus | exitstatus | executionexception | persistentuserdata | readcount | writecount | commitcount | rollbackcount | readskipcount | processskipcount | filtercount | writeskipcount | readercheckpointinfo | writercheckpointinfo
-----------------+----------------+---------+----------+-------------------------+-------------------------+-------------+------------+--------------------+--------------------+-----------+------------+-------------+---------------+---------------+------------------+-------------+----------------+----------------------+----------------------
186 | 161 | | step1 | 2014-02-16 10:58:59.037 | 2014-02-16 10:58:59.04 | COMPLETED | STOP | | | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
187 | 162 | | step2 | 2014-02-16 10:59:00.051 | 2014-02-16 10:59:00.054 | COMPLETED | COMPLETED | | | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
(2 rows)
- 一応予想通り動いたけど、ログにWARNで出ている文言が気になる
- 再実行時に初回実行時に実行してないStepから再開するっていうのは仕様上微妙なのかも
備考
- on属性にはワイルドカード(*と?)が使える
- next on=“*” とかよく使いそう
- endは正常系で後続処理やらなくて良い時に使う感じ。非営業日だから何もせずに終わりとか(営業日関連はジョブ内でやらずに、ジョブ呼び出すところを作り込んでジョブが動く前に止めた方がいい気がするけど)
- failは異常系の時(例外投げてもいい気がするけど)
- stopは再実行前提で止めたい時とか、再実行するstepを制御したい時に使う?どういう状況で使うのかいまいち想像できないけど
- 先行処理の状況から分岐させたいときは、StepExecutionの配列を受け取ってExitStatusを決められるDeciderを使うのが良い
参考文献
Tags: jbatch