Entries tagged [jbatch]
CLIからリモートEJB経由でジョブを操作してみる
TweetPosted on Monday Feb 10, 2014 at 06:44PM in Technology
JAX-RSなどを使ってREST APIを作る方が良いのだろうと思われるが、大変なのでリモートEJB経由でやってみる。さらにコマンドラインから叩きたいので、シェルスクリプトから蹴れるように少し作り込んでみる
WildFly - リモートEJB呼び出しを使ってみる を併せて読むと多少参考になるかも
環境
- WildFly8.0.0.CR1
- Oracle JDK7u51
- OS X 10.9.1
準備
プロジェクトを作る
下の3つを作る。ソースはGitHubに置いた
- JSR352APIのSerializableなJavaBeansを含むプロジェクト(jbatchif)
- リモートEJBとバッチの実装を含むプロジェクト(jbatch)
- クライアント側プロジェクト(jbatchcli)
JSR352APIのSerializableなJavaBeansを含むプロジェクト(jbatchif)
SimpleJobInstanceImpl.java, SimpleJobExecutionImpl.java, SimpleStepExecutionImpl.java, SimpleMetricImpl.java
JobInstance, JobExecution, StepExecution, MetricインタフェースのSerializableな実装。WildFlyのJSR352実装のこれらのクラスをそのまま使うとNotSerializableExceptionが出てしまうのでしかたなく作った(org.jberet.runtime.metric.StepMetricsが非Serializableらしい)。リモートEJB側とクライアント側の両方で使うので切り出しておく。フィールドとアクセサしかないただのJavaBeans。
リモートEJBとバッチの実装を含むプロジェクト(jbatch)

MyJobOperatorImpl.java
こいつをリモートEJB経由で呼び出す。throws宣言が若干気になるけど面倒なのでそのままにしておく
TestBatchlet.java, job001.xml
動かしてみる で使ったのと同じ
クライアント側プロジェクト(jbatchcli)
Main.java
メインクラス。引数でリモートEJBのJNDI名、ジョブ名、ジョブパラメータを受け取る。細かい処理はprocessorパッケージの下のクラスにやらせる。Commons CLIとか使って作り込んだ方がいいんだろうけど、現状ではかなり適当。
config.sh
シェルスクリプトの環境依存っぽいところを外だししてある
jbatch.sh
javaコマンドをたたくところ
jndi.properties
リモートEJBのlookupに必要な設定をする。ここを適当に書き換えればWildFly以外のAPサーバでもいけるはず
logging.properties
JBossのEJB呼び出し用ライブラリがデバッグ的な文言をINFOレベルで出力してくるのでログレベル上げて出ないようにしとく
デプロイする
CLIから叩く前にjbatchプロジェクトをデプロイする
CLIから叩いてみる
ジョブ一覧を表示してみる
kyle-no-MacBook:resources kyle$ ./jbatch.sh list-job-names Picked up _JAVA_OPTIONS: -Dfile.encoding=UTF-8 jobNames: [job001] kyle-no-MacBook:resources kyle$
jbatchランタイムに認識されたジョブXMLの一覧的なのが出る。job001しかないので1つだけだけど。
ジョブを起動してみる
kyle-no-MacBook:resources kyle$ ./jbatch.sh start job001 Picked up _JAVA_OPTIONS: -Dfile.encoding=UTF-8 executionId: 63 kyle-no-MacBook:resources kyle$
普通に動いている。WildFly側にもログが出てる。こんな感じ

まだジョブXML一覧と起動のところしか作ってない。停止とか再実行とかexecutionIdから情報見るとかはそのうち作り込む。
何故かなかなかjavaプロセスが終了しないことがあるのが気になる。1分位待ってると終わるんだけど。
参考文献
Tags: jbatch
Chunk方式のStepを使ってみる
TweetPosted on Monday Feb 10, 2014 at 06:42PM in Technology
jbatchでバルク処理を行う場合、Chunk-orientedという方式に合わせたインタフェース群を実装することが推奨されている。若干複雑なので、簡単な実装を作ってみて、ログや仕様を見つつ処理の流れを確認してみる。
JSR 352 Implementation - Connection close probl… | Communityによると、ここに書いてあるような実装はよろしくないようです。SELECT文の発行などは全て同一トランザクション内で完結する必要があるらしい。open()で取得するのはPKだけにして、実際のデータはreadItem()で別途取得するようにするなどした方が良いかも
トランザクション境界を跨いでJDBCの資源(Connection, Statement, ResultSet等)を使う場合は,非JTAデータソースを使いましょう.詳細はこちらを参照.
環境
- WildFly8.0.0.Final
- その他はArquillianでジョブのテストをしてみると同じ
前提条件
Arquillianでジョブのテストをしてみるで作ったプロジェクトが普通に動いているものとする
Chunk-oriented Processingとは
以下の3つのインタフェースで1つのStepが構成される。開発者はこれらのインタフェースを実装したクラスを作って1つのStepを作る
- ItemReader
- ItemProcessor
- ItemWriter
データの入力元と出力先が両方ともDBの場合、それぞれの役割と実装の仕方はざっくり以下のような感じになるかと思われる
ItemReader
SELECT文を実行して処理したい単位でデータを取り出しItemProcessorに渡す。
void open(Serializable)
SELECT文を発行するのが普通の使い方かと思われる。
バッチが初回実行の場合、引数はnullだが、途中でバッチが死んだ後の再実行の場合、checkpointInfo()で返したカウンタが引数で渡されるので、これをうまく使えば処理済みのデータをスキップして途中から処理を再開させられる。
JPAを使う場合
データ量が少ない場合はEntityManagerを使いQueryを作ってgetResultList()を呼ぶ。データ量が多い場合、[4][5][8]あたりを読むと良いかも
JDBCを使う場合
DataSourceを使いConnection, Statement, ResultSetを作る。データ量が多い場合は[6]あたりを読むとよいかも。
Object readItem()
データを1件取り出す処理。データがなくなったらnullを返すと全件処理終了の意味になる。
JPAを使う場合
open()で作ったListからget()でデータを取り出して返す。
JDBCを使う場合
ResultSet#next()を呼んでカーソルを制御しつつ、簡単なものならResultSetをそのまま返すか、ResultSet#get()でデータを取り出して、適当なDTO等につめて返す
void close()
open()で開いた資源を解放する。Connection, Statement, ResultSetを使った場合はここでcloseする。
Serializable checkpointInfo()
カウンタを返す。返したカウンタはRepositoryに保存され、どこまで処理が完了したかが記録される。
ItemProcessor
ItemReaderが取り込んだデータを適当に処理して処理結果を作る。省略可。
Object process(Object)
ItemReader#readItem()が返したオブジェクトがここでの引数になる。これを使って何らかの処理をする。ここで返した処理結果はItemWriter#writeItems()の引数になる
ItemWriter
ItemProcessorが作った処理結果をどこかのテーブルに書き込む。
void open(Serializable)
JDBCを使う場合、ここでConnectionとINSERT/UPDATE/DELETE文のPreparedStatementを開いておいたりすると良いのかも たぶん何もしない.
void writeItems(List)
ItemProcessorが作った処理結果が1トランザクションで書き込む単位でまとめてListに詰めて引数で渡されるので、ループ等を使って要素をどこかのテーブルに書き込む。
JPAを使う場合
EntityManager#persist()かmerge()を呼び出す。
JDBCを使う場合
open()で開いておいたConnection, PreparedStatementを作って,データを書き込む。
void close()
Connection, Statementを使った場合はここで閉じる たぶん何もしない.
Serializable checkpointInfo()
ItemReaderの同メソッドと同じ。
準備
単純なchunk方式のStepが1つだけのバッチをJPAを使って作ってみる。資源の詳細はこのあたり参照
バッチを構成する資源
ChunkInputItem.java, ChunkOutputItem.java
超単純なエンティティ。
- ItemReaderがChunkInputItemを取ってくる
- ItemProcessorがChunkInputItemをChunkOutputItemに変換する
- ItemWriterがChunkOutputItemをDBに書き込む
chunk.xml
- ジョブXML。chunk方式のStep1個だけの単純なもの
- 3件処理したらコミット
- processorにジョブパラメータを渡してみる
ChunkItemReader.java
- データ量が多い場合はよろしくないが、簡単のためgetResultList()でデータを取ってくる
- 一応カウンタ付き
ChunkItemProcessor.java
- @BatchPropertyで受け取ったプロパティを使って、@PostConstructで初期化的な処理をやってみる
- ChunkInputItemからChunkOutputItemを作って返す
ChunkItemWriter.java
- EntityManager#persist()を呼ぶ
- 一応カウンタ付き
テスト用資源
ChunkJobTest.java
- テストクラス
- ジョブプロパティを渡してみる
ChunkInputItem.yml, ChunkOutputItem.yml
- テストデータ
- ChunkInputItemは10件
- ChunkOutputItemは0件
expected.yml
- ChunkOutputItemへの出力の期待結果
実行してみる
テスト結果は普通に緑色になる。ログはこんな感じ
22:00:29,478 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemProcessor] (batch-batch - 3) chunkItemProcessor#postConstruct(): divide=2 22:00:29,478 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#open(): checkpoint=null, index starts at=0 22:00:29,481 DEBUG [org.hibernate.SQL] (batch-batch - 3) select chunkinput0_.id as id1_0_, chunkinput0_.input as input2_0_, chunkinput0_.processed as processe3_0_ from ChunkInputItem chunkinput0_ order by chunkinput0_.id 22:00:29,491 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#open(): checkpoint=null, index starts at=0 22:00:29,492 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): index=0 22:00:29,492 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): returning=ChunkInputItem [id=0, input=0, processed=false] 22:00:29,492 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemProcessor] (batch-batch - 3) chunkItemProcessor#processItem(): input=ChunkInputItem [id=0, input=0, processed=false], output=ChunkOutputItem [id=0, result=0] 22:00:29,492 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=1 22:00:29,492 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): index=1 22:00:29,492 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): returning=ChunkInputItem [id=1, input=10, processed=false] 22:00:29,492 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemProcessor] (batch-batch - 3) chunkItemProcessor#processItem(): input=ChunkInputItem [id=1, input=10, processed=false], output=ChunkOutputItem [id=1, result=5] 22:00:29,492 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=2 22:00:29,493 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): index=2 22:00:29,493 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): returning=ChunkInputItem [id=2, input=20, processed=false] 22:00:29,493 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemProcessor] (batch-batch - 3) chunkItemProcessor#processItem(): input=ChunkInputItem [id=2, input=20, processed=false], output=ChunkOutputItem [id=2, result=10] 22:00:29,493 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=3 22:00:29,493 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): index=0 22:00:29,493 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): item=ChunkOutputItem [id=0, result=0] 22:00:29,493 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): item=ChunkOutputItem [id=1, result=5] 22:00:29,494 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): item=ChunkOutputItem [id=2, result=10] 22:00:29,494 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=3 22:00:29,494 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#checkpointInfo(): returns=1 22:00:29,494 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=3 22:00:29,497 DEBUG [org.hibernate.SQL] (batch-batch - 3) insert into ChunkOutputItem (result, id) values (?, ?) 22:00:29,505 DEBUG [org.hibernate.SQL] (batch-batch - 3) insert into ChunkOutputItem (result, id) values (?, ?) 22:00:29,506 DEBUG [org.hibernate.SQL] (batch-batch - 3) insert into ChunkOutputItem (result, id) values (?, ?) 22:00:29,507 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): index=3 22:00:29,507 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): returning=ChunkInputItem [id=3, input=30, processed=false] 22:00:29,507 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemProcessor] (batch-batch - 3) chunkItemProcessor#processItem(): input=ChunkInputItem [id=3, input=30, processed=false], output=ChunkOutputItem [id=3, result=15] 22:00:29,507 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=4 22:00:29,507 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): index=4 22:00:29,508 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): returning=ChunkInputItem [id=4, input=40, processed=false] 22:00:29,508 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemProcessor] (batch-batch - 3) chunkItemProcessor#processItem(): input=ChunkInputItem [id=4, input=40, processed=false], output=ChunkOutputItem [id=4, result=20] 22:00:29,508 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=5 22:00:29,508 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): index=5 22:00:29,508 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): returning=ChunkInputItem [id=5, input=50, processed=false] 22:00:29,508 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemProcessor] (batch-batch - 3) chunkItemProcessor#processItem(): input=ChunkInputItem [id=5, input=50, processed=false], output=ChunkOutputItem [id=5, result=25] 22:00:29,508 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=6 22:00:29,508 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): index=1 22:00:29,508 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): item=ChunkOutputItem [id=3, result=15] 22:00:29,509 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): item=ChunkOutputItem [id=4, result=20] 22:00:29,509 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): item=ChunkOutputItem [id=5, result=25] 22:00:29,509 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=6 22:00:29,509 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#checkpointInfo(): returns=2 22:00:29,509 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=6 22:00:29,510 DEBUG [org.hibernate.SQL] (batch-batch - 3) insert into ChunkOutputItem (result, id) values (?, ?) 22:00:29,512 DEBUG [org.hibernate.SQL] (batch-batch - 3) insert into ChunkOutputItem (result, id) values (?, ?) 22:00:29,513 DEBUG [org.hibernate.SQL] (batch-batch - 3) insert into ChunkOutputItem (result, id) values (?, ?) 22:00:29,514 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): index=6 22:00:29,514 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): returning=ChunkInputItem [id=6, input=60, processed=false] 22:00:29,514 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemProcessor] (batch-batch - 3) chunkItemProcessor#processItem(): input=ChunkInputItem [id=6, input=60, processed=false], output=ChunkOutputItem [id=6, result=30] 22:00:29,514 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=7 22:00:29,514 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): index=7 22:00:29,514 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): returning=ChunkInputItem [id=7, input=70, processed=false] 22:00:29,514 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemProcessor] (batch-batch - 3) chunkItemProcessor#processItem(): input=ChunkInputItem [id=7, input=70, processed=false], output=ChunkOutputItem [id=7, result=35] 22:00:29,514 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=8 22:00:29,514 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): index=8 22:00:29,514 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): returning=ChunkInputItem [id=8, input=80, processed=false] 22:00:29,514 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemProcessor] (batch-batch - 3) chunkItemProcessor#processItem(): input=ChunkInputItem [id=8, input=80, processed=false], output=ChunkOutputItem [id=8, result=40] 22:00:29,515 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=9 22:00:29,515 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): index=2 22:00:29,515 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): item=ChunkOutputItem [id=6, result=30] 22:00:29,515 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): item=ChunkOutputItem [id=7, result=35] 22:00:29,515 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): item=ChunkOutputItem [id=8, result=40] 22:00:29,515 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=9 22:00:29,516 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#checkpointInfo(): returns=3 22:00:29,516 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=9 22:00:29,516 DEBUG [org.hibernate.SQL] (batch-batch - 3) insert into ChunkOutputItem (result, id) values (?, ?) 22:00:29,517 DEBUG [org.hibernate.SQL] (batch-batch - 3) insert into ChunkOutputItem (result, id) values (?, ?) 22:00:29,517 DEBUG [org.hibernate.SQL] (batch-batch - 3) insert into ChunkOutputItem (result, id) values (?, ?) 22:00:29,518 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): index=9 22:00:29,519 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): returning=ChunkInputItem [id=9, input=90, processed=false] 22:00:29,519 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemProcessor] (batch-batch - 3) chunkItemProcessor#processItem(): input=ChunkInputItem [id=9, input=90, processed=false], output=ChunkOutputItem [id=9, result=45] 22:00:29,519 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=10 22:00:29,519 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): index=10 22:00:29,519 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#readItem(): returning=null 22:00:29,519 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): index=3 22:00:29,519 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#writeItems(): item=ChunkOutputItem [id=9, result=45] 22:00:29,519 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=10 22:00:29,520 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#checkpointInfo(): returns=4 22:00:29,520 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#checkpointInfo(): returns=10 22:00:29,520 DEBUG [org.hibernate.SQL] (batch-batch - 3) insert into ChunkOutputItem (result, id) values (?, ?) 22:00:29,522 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#close() 22:00:29,522 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#close() 22:00:29,522 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemReader] (batch-batch - 3) chunkItemReader#close() 22:00:29,522 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 3) chunkItemWriter#close()
処理の流れを見てみる
[2]の「11.6 Regular Chunk Processing」に詳細が書いてあるが、以下のようなイメージの順序で処理が行われる
まずopenが呼ばれる(ログの2-4行目)
- トランザクション開始
- ItemReader#open()
- ItemWriter#open()
- コミット
データがなくなる(readItem()がnullを返す)まで以下ループ(ログの5-26行目)
- トランザクション開始
- ItemReader#readItem()
- ItemProcessor#processItem()
- ItemReader#readItem()
- ItemProcessor#processItem()
- ItemReader#readItem()
- ItemProcessor#processItem()
- itemWriter#writeItems() ※ItemProcessor#processItem()の返り値3件分がListに詰められたものが引数
- ItemReader#checkpointInfo()をRepositoryに記録
- ItemWriter#checkpointInfo()をRepositoryに記録
- コミット
ItemReader#readItem()で件数カウンタをインクリメントしつつデータを1件返す。ItemProcessor#processItem()にデータが渡ってきたら、処理を行い、結果をreturnで返す。これがitem-countに指定した数繰り返され、処理結果がListに詰められてItemWriter#writeItems()に渡される。ここでも件数カウンタをインクリメントしつつ書き込む。コミット前にItemReaderとItemWriterのcheckpointInfo()が呼ばれ、件数カウンタがRepositoryに書き込まれる。
件数カウンタを実装しておくと、処理中に問題が起きた後の再実行時に処理済みのデータをスキップさせることが可能になる。再実行時のスキップが必要ない場合は、AbstractItemReaderを継承して、Iteratorを使うと楽に実装できる。
なお、アプリで使っているものとRepositoryのものとは通常別のデータソースになるので、基本的にXAトランザクションが必要になるようだ.または,XAトランザクションを使いたくない場合は,Repository用のデータソースを非JTAデータソースにするといいかもしれない.
最後にcloseが呼ばれる(ログの83-86行目)
- トランザクション開始
- ItemReader#close()
- ItemWriter#close()
- コミット
備考
- ItemReader#close()とItemWriter#close()の呼ばれる順序が仕様[2]と逆な気がする。仕様だとItemWriter#close()→ItemReader#close()の順だが、この実装だとItemReader#close()→ItemWriter#close()の順に呼ばれている
- ItemReaderとItemWriterのclose()が2回呼ばれるのが気になる。[3]を見るとsafeClose()ってとこで例外を握りつぶしつつ、しつこくclose()するようになってる。まあこれはこれでいいのかも
- checkpointInfo()も無駄に呼ばれている気がする。けど別に害は無いだろうから気にしない
- JDBCを使う場合はDbUtils.closeQuietly()があると便利かも。ResultSetHandlerは使い辛そう
続き
参考文献
- Batch Application for the Java Platform – JSR352
- JSR-000352 Batch Applications for the Java Platform - Final Release
- jsr352/jberet-core/src/main/java/org/jberet/runtime/runner/ChunkRunner.java at master · jberet/jsr352
- java - How to handle large dataset with JPA (or at least with Hibernate)? - Stack Overflow
- java - JPA: what is the proper pattern for iterating over large result sets? - Stack Overflow
- java - JDBC: How to read all rows from huge table? - Stack Overflow
- 調査メモ: DbUtilsのサンプル
- JPAからフェッチサイズを変更したかった - kagamihogeの日記
Tags: jbatch
WildFly8でJDBCジョブレポジトリを使ってみる
TweetPosted on Saturday Feb 08, 2014 at 04:36PM in Technology
WildFly8.0.0.CR1ではジョブレポジトリがデフォルトではインメモリH2になっているが、スタンドアロンのDBにしてみる。現状H2しかサポートしてないようなのでサーバモードのH2を立ててやってみる
この例では普通のデータソースを使ってますが、バッチから他のデータベースも参照する場合は、XAデータソースにしておかないと問題が起こると思われるので注意
環境
- WildFly8.0.0.CR1
- H2 1.3.175 (2014-01-18)
- Oracle JDK7u51
- OS X 10.9.1
準備
プロジェクト
動かしてみるで作ったプロジェクトをそのまま使う。
H2を立ち上げる
- H2のzipファイルをとってきて展開する
- h2/binに存在するh2.shを実行する
- ブラウザにH2管理コンソールへのログイン画面が表示される。デフォルトでTCP接続のH2にログインする内容になっているのでそのままログインする
- 適当にSQLを実行してみて普通に動いている事を確認する
データソースを作る
jboss-cliで叩くコマンドはこんな感じ。この環境だとH2は最初から入っているようなので特にJDBCドライバのデプロイ等は不要。
data-source add \
--name=JBatchDS \
--driver-name=h2 \
--connection-url=jdbc:h2:tcp://localhost/~/test \
--jndi-name=java:jboss/jdbc/JBatchDS \
--user-name=sa \
--password=
一応接続チェック
[standalone@localhost:9990 /] /subsystem=datasources/data-source=JBatchDS:test-connection-in-pool
{
"outcome" => "success",
"result" => [true]
}
ジョブレポジトリを変更
JDBCレポジトリのデータソース名を設定
[standalone@localhost:9990 /] /subsystem=batch/job-repository=jdbc:write-attribute(name=jndi-name, value=java:jboss\/jdbc\/JBatchDS)
{
"outcome" => "success",
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
}
job-repository-typeをjdbcに設定
[standalone@localhost:9990 /] /subsystem=batch:write-attribute(name=job-repository-type, value=jdbc)
{
"outcome" => "success",
"response-headers" => {
"operation-requires-restart" => true,
"process-state" => "restart-required"
}
}
restart-requiredだそうなので再起動する。
実行してみる
TestServletにアクセス
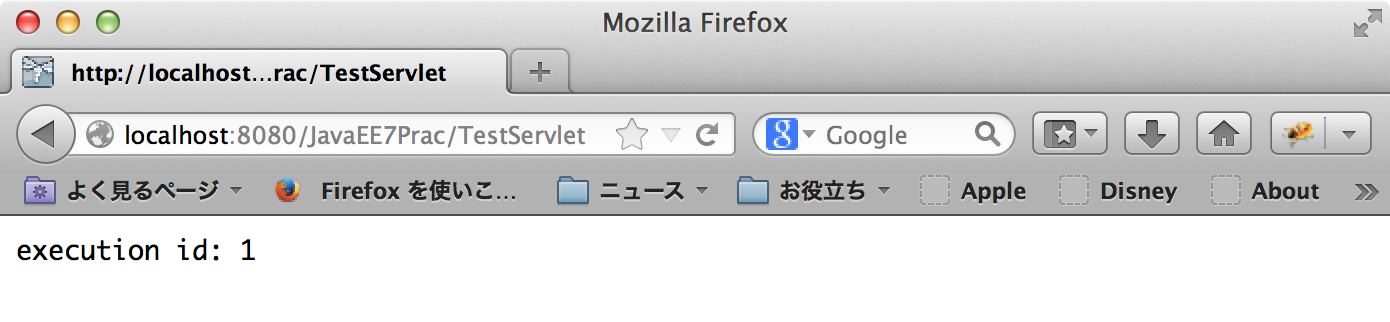
普通に動いているようです
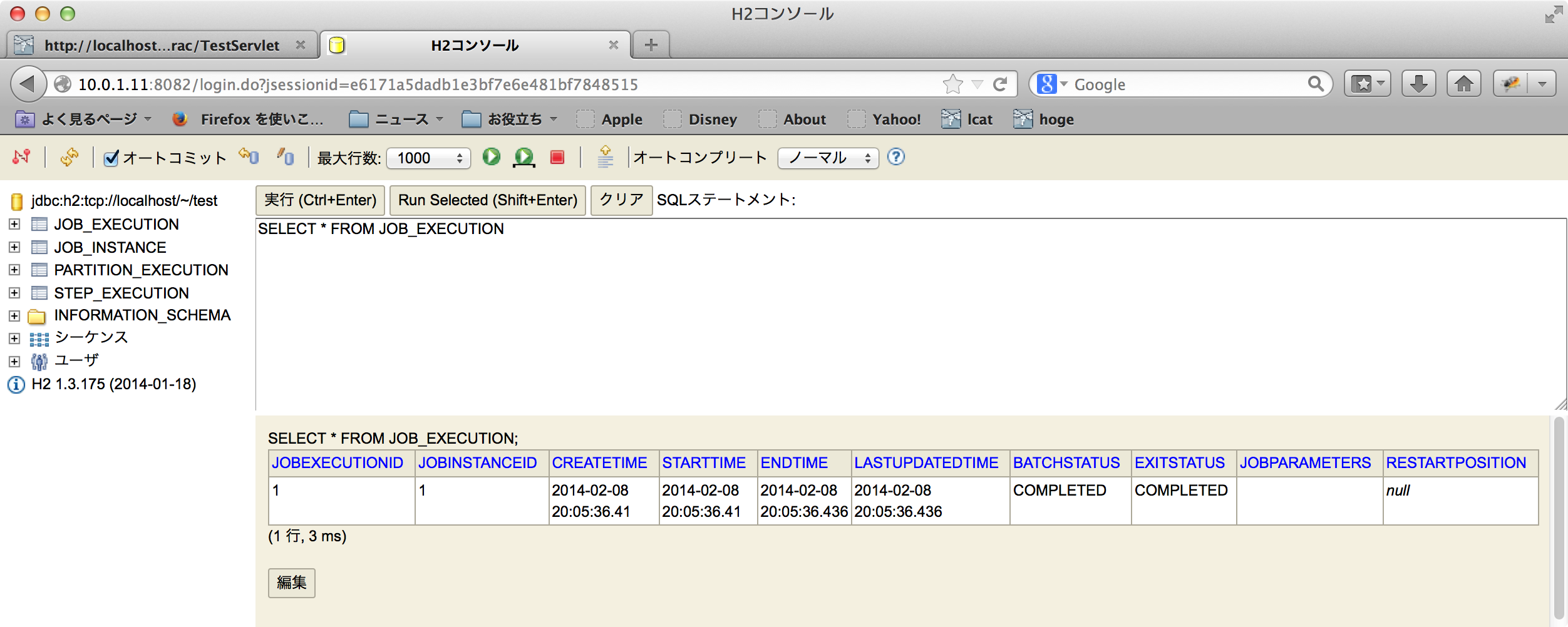
DBを見てみる
事前にDDLを流したりは一切していないが、H2のWebコンソールから見てみると自動的に必要なテーブル等が作られている
備考
GlassFishにあるlist-batch-jobs的なコマンドがあれば良いのだけどまだ見つけられていない。また調べる
参考文献
Tags: jbatch
動かしてみる
TweetPosted on Tuesday Jan 21, 2014 at 06:40AM in JBatch
jbatch(JSR352)とはJavaEE7から入ったバッチフレームワークの規格です。WildFly8ではGlassFish4とは別の実装が使われています。すごく簡単なのをWildFly8で動かしてみます。
環境
- WildFly 8.0.0CR1
- Eclipse等々はここで設定した状態
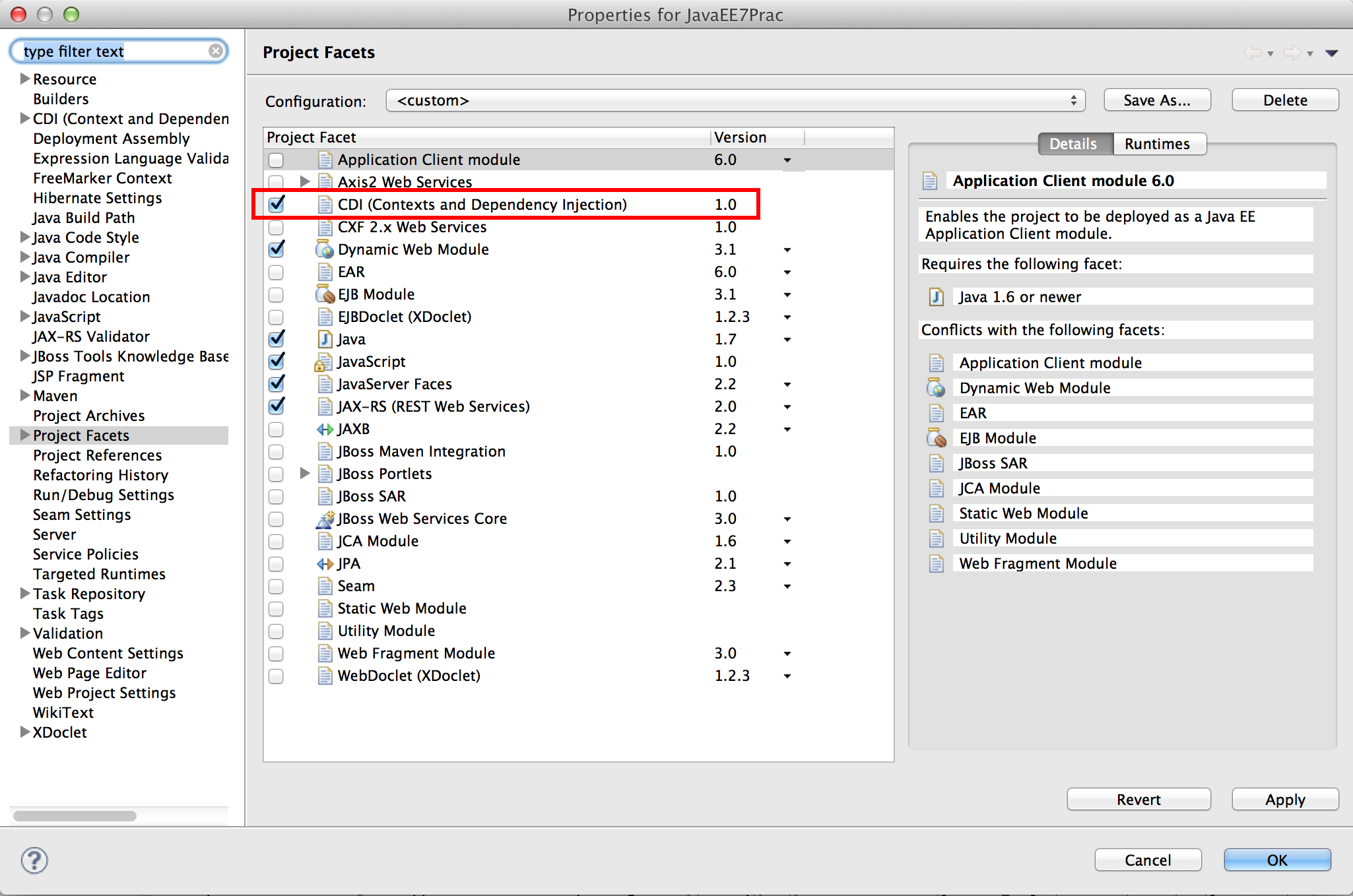
CDIの設定をする
プロジェクトの設定を開いてProject Facetsを選びCDIにチェックを入れてOKを押します。
ジョブXMLファイルを作る
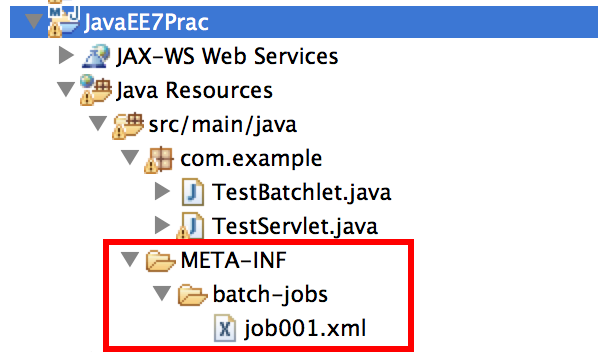
ジョブを起動すると、まずこのXMLファイルがロードされます。JSR352ではアプリ開発者はこのXMLファイルとartifactと呼ばれるクラス群を作る必要があります。まずXMLファイルが読まれ、ここに書かれた通りにartifactが呼び出されます。
作る場所はこのへん.画像では/src/main/javaの下になっていますが,XMLファイル等のJavaソース以外のものは/src/main/resourcesに置くのが望ましいです.war内の位置で言うとclasses/META-INFの下になります。このファイルの名前がバッチの名前になります。
<?xml version="1.0" encoding="UTF-8"?> <job id="job001" version="1.0" xmlns="http://xmlns.jcp.org/xml/ns/javaee"> <step id="step001"> <batchlet ref="testBatchlet"/> </step> </job>
Batchletを作る
Batchletは簡単な処理を書くときに使います。バルク処理とかをやるときは、ここで紹介するBatchletではなく、chunk方式と呼ばれるartifactを使ったほうがよいです。作るクラス1つだけで簡単なのでここではBatchletを作ります。XMLファイルとartifactはCDIの名前でひも付けるので、作る場所はどこでも良いです。
package com.example;
import javax.batch.api.AbstractBatchlet;
import javax.inject.Named;
@Named
public class TestBatchlet extends AbstractBatchlet{
@Override
public String process() throws Exception {
System.out.println("Hello JSR352");
return "SUCCESS";
}
}
Servletを作る
バッチを動かす際の起点にします。ブラウザでServletにGETを飛ばすとバッチが動き出す感じです。定時実行とかスケジュール実行がしたければEJBタイマでやることもできます。
package com.example;
import java.io.IOException;
import java.util.Properties;
import javax.batch.runtime.BatchRuntime;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@WebServlet("/TestServlet")
public class TestServlet extends HttpServlet {
protected void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException {
long executionId = BatchRuntime.getJobOperator().start("job001", new Properties());
response.getWriter().write("execution id: " + executionId);
}
}
動かしてみる
デプロイしたらブラウザでアクセスしてみましょう

動いているようです。それっぽいログも出ています

ジョブを実行するとDB等にかなり詳細な履歴が残せるのですが、WildFly8のデフォルトではインメモリデータベースに格納されるだけになっているようで、後から参照する方法とかは少し調べましたが不明です。DBに残すようにする設定の方法はまた別途調べる予定。
JobOperator#start()で返るのはexecutionIdといって、このIDを使って実行中のバッチを止めたり、途中で死んだバッチを再実行したりできます。バッチの実行ごとに採番されます。リロードすると数字がインクリメントされていきます。
Tags: jbatch