Entries tagged [jberet]
Multiple deployment use mode is implemented to jberetweb
TweetPosted on Thursday Jan 15, 2015 at 09:06PM in jberetweb
Now jberetweb can operate (start, stop, etc) distributed batches in multiple deployment. to enable multiple deployment use mode, suppress -DjobOperator.jndi and specify -DjobOperator.name=${facade-class-name} (e.g. JobOperatorFacade) in mvn option when you build it.
In multiple deployment use mode, "App Name" column will be added for grasp where is deployment of each job comprehensively. actions such as restart, stop will be executed through lookup of appropriate remote EJB interface in according to "App Name".
Also in Start Job window, "App Name" can be specified. this will lookup appropriate remote interface accordingly too.
Index needed on jobexecutionid column in step_execution table
TweetPosted on Monday Jan 05, 2015 at 09:56PM in jberetweb
Today I deployed new jberetweb to my production system which have 1 million rows in step_execution table, and felt jberetweb slow. I looked it and found the cause is sequential scan.
jbatch=# explain analyze select * from step_execution where jobexecutionid = 384846;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Seq Scan on step_execution (cost=0.00..36817.53 rows=4 width=626) (actual time=101.046..101.047 rows=2 loops=1)
Filter: (jobexecutionid = 384846)
Rows Removed by Filter: 1102459
Total runtime: 101.074 ms
So I created an index on jobexecutionid column in step_execution table, then jberetweb starts running fast.
jbatch=# create index step_execution_jobexecutionid_idx on step_execution (jobexecutionid);
CREATE INDEX
jbatch=# explain analyze select * from step_execution where jobexecutionid = 384846;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------
Index Scan using step_execution_jobexecutionid_idx on step_execution (cost=0.43..8.50 rows=4 width=626) (actual time=0.054..0.056 rows=2 loops=1)
Index Cond: (jobexecutionid = 384846)
Total runtime: 0.113 ms
Maybe more indexes are needed for default JBeret schema if I implement some filtering function to jberetweb.
Job operation features are implemented to jberetweb
TweetPosted on Sunday Jan 04, 2015 at 09:26PM in jberetweb
Now jberetweb is able to operate JobOperator interface through remote EJB invocation, so finally jberetweb can start batch jobs. the Start Job window popups when "Start Job" anchor is clicked on the upper right corner. here's a screenshot:
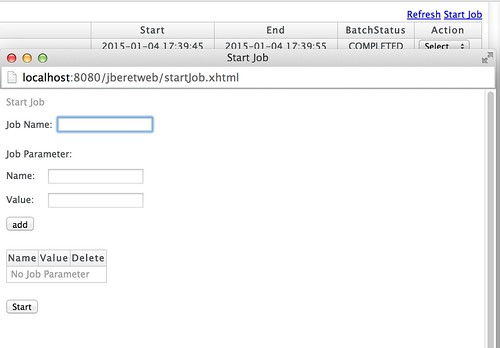
To use this feature, some preparation are needed. first, you have to expose a remote EJB interface of javax.batch.operations.JobOperator from your batch application archive. an example of simplest one is available here. also entire of the project is here.
You can just put this class to any package in your batch application archive. after that, you can see some notification of JNDI names in your WildFly console at every deployment like this:
21:06:45,501 INFO [org.jboss.as.ejb3.deployment.processors.EjbJndiBindingsDeploymentUnitProcessor] (MSC service thread 1-10) JNDI bindings for session bean named JobOperatorFacade in deployment unit deployment "jbatchtest-1.0-SNAPSHOT.war" are as follows: java:global/jbatchtest-1.0-SNAPSHOT/JobOperatorFacade!javax.batch.operations.JobOperator java:app/jbatchtest-1.0-SNAPSHOT/JobOperatorFacade!javax.batch.operations.JobOperator java:module/JobOperatorFacade!javax.batch.operations.JobOperator java:jboss/exported/jbatchtest-1.0-SNAPSHOT/JobOperatorFacade!javax.batch.operations.JobOperator java:global/jbatchtest-1.0-SNAPSHOT/JobOperatorFacade java:app/jbatchtest-1.0-SNAPSHOT/JobOperatorFacade java:module/JobOperatorFacade
Then save first one of yours ("java:global/jbatchtest-1.0-SNAPSHOT/JobOperatorFacade!javax.batch.operations.JobOperator" for example), then put that string to a build parameter of jberetweb (after "-DjobOperator.jndi="). please refer "How to use" section of README.md for build instruction.
Other operations such as restart, stop, abandon are implemented too so I will write more about it later. jberetweb can be obtained from GitHub.
jberetweb, JBeret job repository viewer
TweetPosted on Friday Jan 02, 2015 at 01:01AM in jberetweb
What are JBeret and jberetweb?
JBeret is the out-of-the-box JSR352 JBatch implementation of the WildFly application server. It manages its statuses of jobs and steps in several types of data storage, like RDBMS, which is called repository. But it has no management console or even a standardized way to see it efficiently (I've been watching the repository through SQL!). So, I have created jberetweb as a small web application which shows the JDBC job repository of JBeret.
jberetweb can be obtained at GitHub.
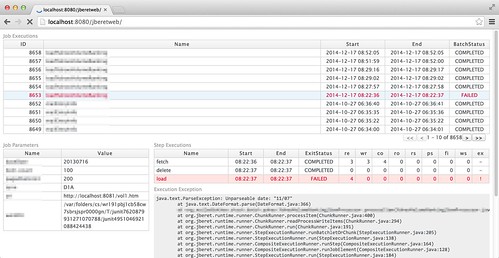
What can be done with jberetweb?
It shows recent job executions with their names, the start/end time and the batch status on the table in the upper half of the page. These rows are clickable. Additional information, like job parameters and step executions, will be shown when any row of the job executions table is clicked. Execution exception data will be shown if the step has failed because an exception occurred. Any problematic rows, such as a failed execution or step, are highlighted. Thanks to JSF's partial rendering and Ajax, paging and operations are fast.
How do I install it?
As I described at README.md in GitHub repository of it, you have to clone and build it with mvn yourself, and some configuration is needed for WildFly before deploying the WAR.
- Create a database on PostgreSQL (jberetweb should run on any other RDBMS, but I haven't tested yet)
- Register a XA data source for the job repository
- Register JNDI name of the JDBC job repository
- Set the job repository type as JDBC
- Define JSF project stage to JNDI
batch
xa-data-source add \
--name=JBatchDS \
--driver-name=postgresql \
--jndi-name=java:jboss/jdbc/JBatchDS \
--user-name=postgres \
--password=***
/subsystem=datasources/xa-data-source="JBatchDS"/xa-datasource-properties=ServerName:add(value="localhost")
/subsystem=datasources/xa-data-source="JBatchDS"/xa-datasource-properties=PortNumber:add(value="5432")
/subsystem=datasources/xa-data-source="JBatchDS"/xa-datasource-properties=DatabaseName:add(value="jbatch")
run-batch
/subsystem=batch/job-repository=jdbc:write-attribute(name=jndi-name, value=java:jboss/jdbc/JBatchDS)
/subsystem=batch:write-attribute(name=job-repository-type, value=jdbc)
/subsystem=naming/binding=java\:\/env\/jsf\/ProjectStage:add(binding-type=simple,value=Development,class=java.lang.String)
NOTE:
- JBeret creates the schema automatically if any tables aren't found, so make sure the database user can execute DDLs.
- Use XA datasource for both the job repository and your application database.
Here's some related pointers:
- [WFLY-3174] Add view of batch jobs with ability to view, restart and stop - JBoss Issue Tracker
- JSR 352 - Viewing batch jobs in admin console | JBoss Developer
I would be grateful for your feedback because it's my first software which is public on GitHub.