jQuery DataTables with JAX-RS
TweetPosted on Monday Mar 24, 2014 at 05:21PM in Technology
- jQuery DataTables plugin can delegate some data processing to server-side with interaction with JSON[2].
- It's efficient way when we have to go with large data sets.
- So I have tried it with JAX-RS.
Environment
- DataTables 1.9.4
- WildFly 8.0.0.Final
- Oracle JDK8
- PostgreSQL 9.2.4
Sample data
- In this example, we use some tables on PostgreSQL as the data source.
- These tables are parts of the job repository of jBeret (jBatch implementation of WildFly).
- We will execute a SQL which returns data set like this:
jobexecutionid | jobname | starttime | endtime | batchstatus
----------------+---------+-------------------------+-------------------------+-------------
2167 | myjob | 2014-03-19 14:31:13.343 | | STARTING
2166 | myjob | 2014-03-19 14:14:38.158 | 2014-03-19 14:14:59.388 | FAILED
2165 | myjob | 2014-03-19 14:13:24.104 | 2014-03-19 14:14:25.59 | STOPPED
2164 | myjob | 2014-03-19 14:11:32.238 | | STARTING
2163 | myjob | 2014-03-19 14:03:41.07 | 2014-03-19 14:10:29.391 | STOPPED
2162 | myjob | 2014-03-19 13:54:41.017 | 2014-03-19 13:56:55.365 | STOPPED
2161 | myjob | 2014-03-19 13:54:26.902 | 2014-03-19 13:54:38.077 | STOPPED
2160 | myjob | 2014-03-19 13:53:49.291 | 2014-03-19 13:54:22.496 | STOPPED
(8 rows)
jbatch=#
Resources
JobExecutionReportService.java
- Make sure a datasource named “java:jboss/jdbc/JBatchDS” configured correctly on the application server.
package org.nailedtothex.jaxrs_datatables;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import javax.ejb.Stateless;
import javax.sql.DataSource;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.QueryParam;
import javax.ws.rs.core.MediaType;
import java.sql.*;
import java.text.Format;
import java.text.MessageFormat;
import java.util.*;
@Stateless
@Path("/JobExecutionReportService")
public class JobExecutionReportService {
private static final String SQL_COUNT = "SELECT COUNT(1) FROM job_execution";
private static final String SQL_FETCH = "SELECT\n" +
" e.jobexecutionid,\n" +
" i.jobname,\n" +
" e.starttime,\n" +
" e.endtime,\n" +
" e.batchstatus\n" +
"FROM\n" +
" job_execution e\n" +
" LEFT JOIN job_instance i ON e.jobinstanceid = i.jobinstanceid\n" +
"ORDER BY\n" +
" e.jobexecutionid {0}\n" +
"LIMIT ?\n" +
"OFFSET ?";
private static final Set<String> VALID_SORT_DIR = Collections.unmodifiableSet(new HashSet<>(Arrays.asList("asc", "desc")));
@Resource(lookup = "java:jboss/jdbc/JBatchDS")
private DataSource ds;
private Format sqlFormat;
@PostConstruct
protected void init() {
sqlFormat = new MessageFormat(SQL_FETCH);
}
@GET
@Produces(MediaType.APPLICATION_JSON)
public DataTablesBean getJobExecutionReport(
@QueryParam("sEcho") Integer sEcho,
@QueryParam("iDisplayLength") Integer iDisplayLength,
@QueryParam("iDisplayStart") Integer iDisplayStart,
@QueryParam("sSortDir_0") String sSortDir_0) throws SQLException {
final Long count;
try (Connection cn = ds.getConnection();
Statement st = cn.createStatement();
ResultSet rs = st.executeQuery(SQL_COUNT);) {
rs.next();
count = rs.getLong(1);
}
if (sSortDir_0 == null || !VALID_SORT_DIR.contains(sSortDir_0)) {
throw new IllegalArgumentException(sSortDir_0);
}
final String sql = sqlFormat.format(new Object[]{sSortDir_0});
final List<List<String>> aaData = new ArrayList<>();
try (Connection cn = ds.getConnection();
PreparedStatement ps = cn.prepareStatement(sql)) {
ps.setInt(1, iDisplayLength);
ps.setInt(2, iDisplayStart);
try (ResultSet rs = ps.executeQuery()) {
final int columns = rs.getMetaData().getColumnCount();
while (rs.next()) {
List<String> data = new ArrayList<>(columns);
for (int i = 1; i <= columns; i++) {
data.add(rs.getString(i));
}
aaData.add(data);
}
}
}
final DataTablesBean bean = new DataTablesBean();
bean.setsEcho(sEcho);
bean.setiTotalDisplayRecords(String.valueOf(count));
bean.setiTotalRecords(String.valueOf(count));
bean.setAaData(aaData);
return bean;
}
}
DataTablesBean.java
package org.nailedtothex.jaxrs_datatables;
import java.util.List;
public class DataTablesBean {
private Integer sEcho;
private String iTotalRecords;
private String iTotalDisplayRecords;
private List<List<String>> aaData;
public String getiTotalRecords() {
return iTotalRecords;
}
public void setiTotalRecords(String iTotalRecords) {
this.iTotalRecords = iTotalRecords;
}
public String getiTotalDisplayRecords() {
return iTotalDisplayRecords;
}
public void setiTotalDisplayRecords(String iTotalDisplayRecords) {
this.iTotalDisplayRecords = iTotalDisplayRecords;
}
public List<List<String>> getAaData() {
return aaData;
}
public void setAaData(List<List<String>> aaData) {
this.aaData = aaData;
}
public Integer getsEcho() {
return sEcho;
}
public void setsEcho(Integer sEcho) {
this.sEcho = sEcho;
}
}
index.html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<link rel="stylesheet" type="text/css"
href="http://ajax.aspnetcdn.com/ajax/jquery.dataTables/1.9.4/css/jquery.dataTables.css">
<script type="text/javascript" charset="utf8"
src="http://ajax.aspnetcdn.com/ajax/jQuery/jquery-1.8.2.min.js"></script>
<script type="text/javascript" charset="utf8"
src="http://ajax.aspnetcdn.com/ajax/jquery.dataTables/1.9.4/jquery.dataTables.min.js"></script>
<script>
$(document).ready(function () {
$('#example').dataTable({
"bFilter": false,
"sPaginationType": "full_numbers",
"aaSorting": [
[ 0, "desc" ]
],
"aoColumns": [
{ "bSortable": true },
{ "bSortable": false },
{ "bSortable": false },
{ "bSortable": false },
{ "bSortable": false }
],
"bProcessing": true,
"bServerSide": true,
"sAjaxSource": "webapi/JobExecutionReportService"
});
});
</script>
<title></title>
</head>
<body>
<table id="example">
<thead>
<tr>
<th>id</th>
<th>jobName</th>
<th>startTime</th>
<th>endTime</th>
<th>batchStatus</th>
</tr>
</thead>
<tbody>
</tbody>
</table>
</body>
</html>
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.nailedtothex</groupId>
<artifactId>jaxrs-datatables</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-api</artifactId>
<version>7.0</version>
</dependency>
</dependencies>
</project>
web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"
version="3.0">
<servlet-mapping>
<servlet-name>javax.ws.rs.core.Application</servlet-name>
<url-pattern>/webapi/*</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
</welcome-file-list>
</web-app>
In action
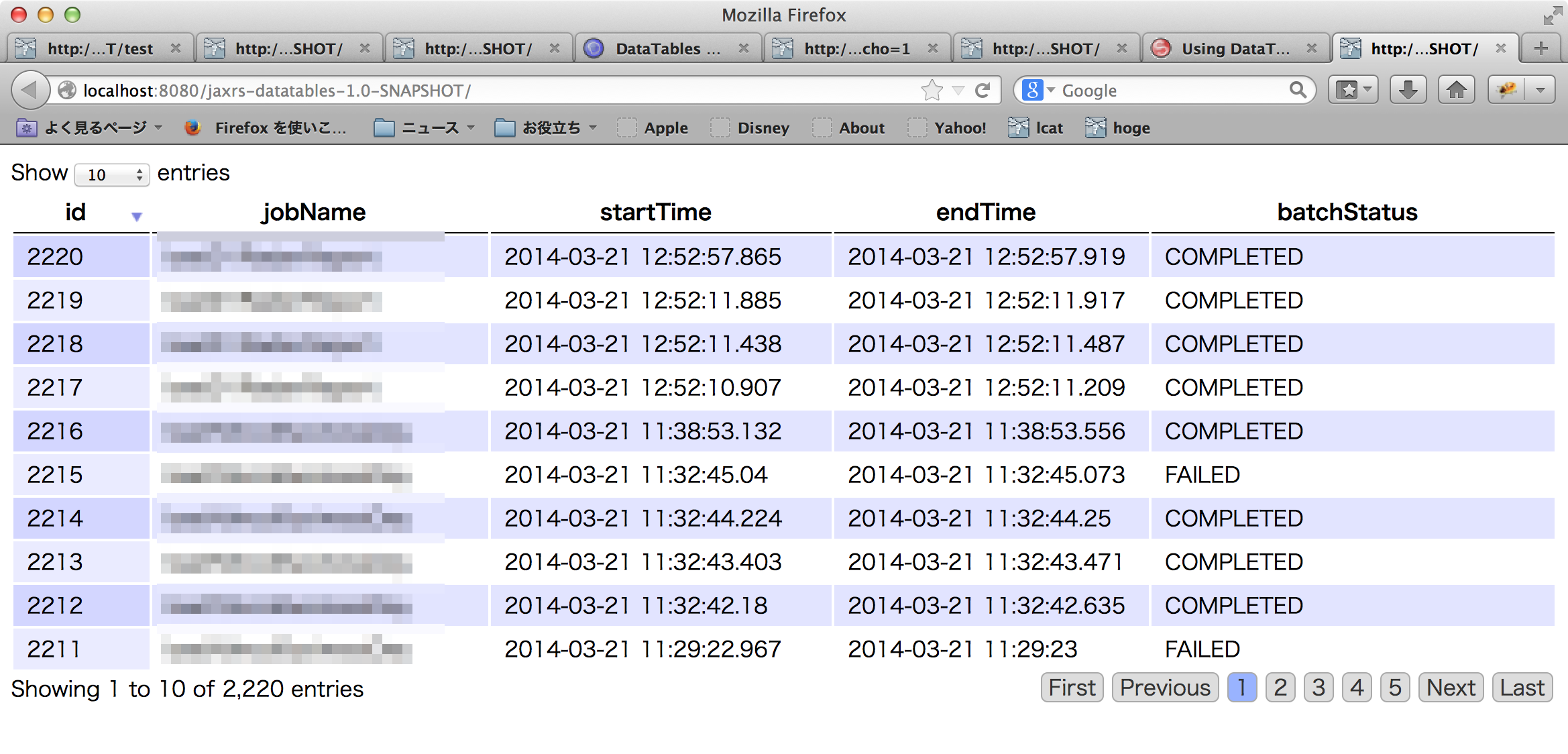
- Pagination and sorting with id are working correctly.
References
Tags: javaee
Partial data dump/restore
TweetPosted on Tuesday Mar 11, 2014 at 03:45PM in Technology
dump data
hogedb=# copy (select * from hogetable where basedate between '20070101' and '20070131') TO '/tmp/1month.sql'; COPY 561368 hogedb=#
dump schema
pg_dump --schema-only -t hogetable hogedb > /tmp/1month.ddl
restore schema
hogedb=# \i /tmp/1month.ddl SET SET SET SET SET SET SET SET CREATE TABLE ALTER TABLE ALTER TABLE ALTER TABLE CREATE INDEX CREATE INDEX hogedb=#
restore data
hogedb=# copy hogetable from '/tmp/1month.sql'; COPY 561368 hogedb=#
References
Tags: postgres
Chunk-oriented Processing with Hibernate's StatelessSession
TweetPosted on Tuesday Mar 11, 2014 at 08:24AM in Technology
- Bulk fetching is difficult with standard JPA API, but provider-specific functions make it easy.
- This is a example of such provider-specific bulk fetching function of Hibernate with JSR352.
According to JSR 352 Implementation - Connection close probl… | Community, this example seems to be wrong. every cursors need to be opened and closed in a transaction. so another approach is required, e.g. fetch primary keys in open(), then fetch each rows in readItem().
Environment
- WildFly8.0.0.Final
- Hibernate 4.3.1.Final
- Oracle JDK7u51
- PostgreSQL 9.2.4
Example
ItemReader
package org.nailedtothex.jbatch.example.chunk;
@Named
public class ChunkItemReader extends AbstractItemReader {
@PersistenceContext
EntityManager em;
ScrollableResults scroll;
StatelessSession ss;
Session session;
@Override
public void open(Serializable checkpoint) throws Exception {
session = em.unwrap(Session.class);
ss = session.getSessionFactory().openStatelessSession();
scroll = ss.createQuery("SELECT c FROM ChunkInputItem c ORDER BY c.id").scroll(ScrollMode.FORWARD_ONLY);
}
@Override
public Object readItem() throws Exception {
if (!scroll.next()) {
return null;
}
return scroll.get(0);
}
@Override
public void close() throws Exception {
try {
scroll.close();
} catch (Exception e) {
}
try {
ss.close();
} catch (Exception e) {
}
try {
session.close();
} catch (Exception e) {
}
}
}
- I'm not sure that close() procedures are mandatory or not.
ItemWriter
package org.nailedtothex.jbatch.example.chunk;
@Named
public class ChunkItemWriter extends AbstractItemWriter {
private static final Logger log = Logger.getLogger(ChunkItemWriter.class.getName());
@Override
public void writeItems(List<Object> items) throws Exception {
log.log(Level.FINE, "chunkItemWriter#writeItems(): {0}", new Object[] { items });
}
}
persistence.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="jbatchsls">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>java:jboss/jdbc/JBatchTestDS</jta-data-source>
<properties>
<property name="javax.persistence.schema-generation.database.action" value="none" />
<property name="hibernate.connection.release_mode" value="on_close"/>
</properties>
</persistence-unit>
</persistence>
- “hibernate.connection.release_mode” property is necessary.
- NOTE: use of this declaration is highly discouraged. see the additional note in the bottom of this article which explains the another way to realize it.
- If this is not set, then you will get:
15:24:59,047 INFO [org.hibernate.engine.jdbc.internal.JdbcCoordinatorImpl] (batch-batch - 19) HHH000106: Forcing container resource cleanup on transaction completion
15:24:59,048 WARN [org.hibernate.engine.jdbc.spi.SqlExceptionHelper] (batch-batch - 19) SQL Error: 0, SQLState: null
15:24:59,048 ERROR [org.hibernate.engine.jdbc.spi.SqlExceptionHelper] (batch-batch - 19) The result set is closed.
15:24:59,048 ERROR [org.jberet] (batch-batch - 19) JBERET000007: Failed to run job chunk, doChunk, org.jberet.job.model.Chunk@16d1364: org.hibernate.exception.GenericJDBCException: could not advance using next()
at org.hibernate.exception.internal.StandardSQLExceptionConverter.convert(StandardSQLExceptionConverter.java:54) [hibernate-core-4.3.1.Final.jar:4.3.1.Final]
at org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:126) [hibernate-core-4.3.1.Final.jar:4.3.1.Final]
at org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:112) [hibernate-core-4.3.1.Final.jar:4.3.1.Final]
at org.hibernate.internal.ScrollableResultsImpl.next(ScrollableResultsImpl.java:125) [hibernate-core-4.3.1.Final.jar:4.3.1.Final]
at org.nailedtothex.jbatch.example.chunk.ChunkItemReader.readItem(ChunkItemReader.java:31) [classes:]
at org.jberet.runtime.runner.ChunkRunner.readItem(ChunkRunner.java:343) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.ChunkRunner.readProcessWriteItems(ChunkRunner.java:288) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.ChunkRunner.run(ChunkRunner.java:190) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.StepExecutionRunner.runBatchletOrChunk(StepExecutionRunner.java:204) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.StepExecutionRunner.run(StepExecutionRunner.java:131) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.CompositeExecutionRunner.runStep(CompositeExecutionRunner.java:162) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.CompositeExecutionRunner.runFromHeadOrRestartPoint(CompositeExecutionRunner.java:88) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.jberet.runtime.runner.JobExecutionRunner.run(JobExecutionRunner.java:58) [jberet-core-1.0.1.Beta-SNAPSHOT.jar:1.0.1.Beta-SNAPSHOT]
at org.wildfly.jberet.services.BatchEnvironmentService$WildFlyBatchEnvironment$1.run(BatchEnvironmentService.java:149) [wildfly-jberet-8.0.0.Final.jar:8.0.0.Final]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) [rt.jar:1.7.0_51]
at java.util.concurrent.FutureTask.run(FutureTask.java:262) [rt.jar:1.7.0_51]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) [rt.jar:1.7.0_51]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) [rt.jar:1.7.0_51]
at java.lang.Thread.run(Thread.java:744) [rt.jar:1.7.0_51]
at org.jboss.threads.JBossThread.run(JBossThread.java:122)
Caused by: java.sql.SQLException: The result set is closed.
at org.jboss.jca.adapters.jdbc.WrappedResultSet.checkState(WrappedResultSet.java:4081)
at org.jboss.jca.adapters.jdbc.WrappedResultSet.next(WrappedResultSet.java:1855)
at org.hibernate.internal.ScrollableResultsImpl.next(ScrollableResultsImpl.java:120) [hibernate-core-4.3.1.Final.jar:4.3.1.Final]
... 16 more
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>jbatchsls</groupId>
<artifactId>jbatchsls</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>war</packaging>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<failOnMissingWebXml>false</failOnMissingWebXml>
</properties>
<dependencies>
<dependency>
<groupId>org.nailedtothex</groupId>
<artifactId>jbatchif</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-api</artifactId>
<version>7.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>4.3.1.Final</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hamcrest</groupId>
<artifactId>hamcrest-core</artifactId>
<version>1.3</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jboss</groupId>
<artifactId>jboss-remote-naming</artifactId>
<version>2.0.0.Final</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jboss.xnio</groupId>
<artifactId>xnio-nio</artifactId>
<version>3.2.0.Final</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
ChunkInputItem
package org.nailedtothex.jbatch.example.chunk;
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class ChunkInputItem implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(nullable = false)
private Long id;
@Column
private Integer input;
@Column
private Boolean processed;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public Integer getInput() {
return input;
}
public void setInput(Integer input) {
this.input = input;
}
public Boolean getProcessed() {
return processed;
}
public void setProcessed(Boolean processed) {
this.processed = processed;
}
@Override
public String toString() {
return "ChunkInputItem [id=" + id + ", input=" + input + ", processed=" + processed + "]";
}
}
Test data
jbatcharts=# select * from chunkinputitem ; id | input | processed ----+-------+----------- 0 | 0 | f 1 | 10 | f 2 | 20 | f 3 | 30 | f 4 | 40 | f 5 | 50 | f 6 | 60 | f 7 | 70 | f 8 | 80 | f 9 | 90 | f (10 rows) jbatcharts=#
Log
15:29:03,916 DEBUG [org.hibernate.SQL] (batch-batch - 20) select chunkinput0_.id as id1_0_, chunkinput0_.input as input2_0_, chunkinput0_.processed as processe3_0_ from ChunkInputItem chunkinput0_ order by chunkinput0_.id 15:29:03,918 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 20) chunkItemWriter#writeItems(): [ChunkInputItem [id=0, input=0, processed=false], ChunkInputItem [id=1, input=10, processed=false], ChunkInputItem [id=2, input=20, processed=false]] 15:29:03,920 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 20) chunkItemWriter#writeItems(): [ChunkInputItem [id=3, input=30, processed=false], ChunkInputItem [id=4, input=40, processed=false], ChunkInputItem [id=5, input=50, processed=false]] 15:29:03,922 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 20) chunkItemWriter#writeItems(): [ChunkInputItem [id=6, input=60, processed=false], ChunkInputItem [id=7, input=70, processed=false], ChunkInputItem [id=8, input=80, processed=false]] 15:29:03,925 FINE [org.nailedtothex.jbatch.example.chunk.ChunkItemWriter] (batch-batch - 20) chunkItemWriter#writeItems(): [ChunkInputItem [id=9, input=90, processed=false]]
A way to avoid “hibernate.connection.release_mode=on_close”
- ItemReader like this works with no declaration of “hibernate.connection.release_mode=on_close” which highly discouraged[2].
public abstract class AbstractHibernateItemReader extends AbstractItemReader {
@PersistenceContext
EntityManager em;
@Resource
DataSource ds;
Connection cn;
ScrollableResults scroll;
StatelessSession ss;
Session session;
@Override
public void open(Serializable checkpoint) throws Exception {
cn = ds.getConnection();
cn.setHoldability(ResultSet.HOLD_CURSORS_OVER_COMMIT);
session = em.unwrap(Session.class);
ss = session.getSessionFactory().openStatelessSession(cn);
scroll = ss.createQuery("SELECT c FROM ChunkInputItem c ORDER BY c.id").scroll(ScrollMode.FORWARD_ONLY);
}
...
@Override
public void close() throws Exception {
try {
scroll.close();
} catch (Exception e) {
}
try {
ss.close();
} catch (Exception e) {
}
try {
session.close();
} catch (Exception e) {
}
try {
cn.close();
} catch (Exception e) {
}
}
...
- Ugly but I guess that it would be better for some occasions.
- There's no proper way to set holdability of resultset with StatelessSession[3].
- Configure through Session#doWork() and SessionImpl#connection() didn't worked as expectedly.
- Both of them brings “The result set is closed”.
References
Tags: jbatch
Using rebase
TweetPosted on Sunday Mar 09, 2014 at 08:17PM in Technology
Make multi commits to one commit with rebase
Commit
kyle-no-MacBook:hello kyle$ echo commit1 >> README.md
kyle-no-MacBook:hello kyle$ git commit -am 'commit1'
[b4 2447554] commit1
1 file changed, 1 insertion(+)
kyle-no-MacBook:hello kyle$ echo commit2 >> README.md
kyle-no-MacBook:hello kyle$ git commit -am 'commit2'
[b4 50e8dee] commit2
1 file changed, 1 insertion(+)
kyle-no-MacBook:hello kyle$ git log -2
commit 50e8deed471c20abc9b86eb1cb7d6b6af4c9fcfd
Author: lbtc-xxx <lbtc-xxx@example.com>
Date: Sun Mar 9 20:17:23 2014 +0900
commit2
commit 2447554c8495ff5f407b4dffb84278840d7fdba6
Author: lbtc-xxx <lbtc-xxx@example.com>
Date: Sun Mar 9 20:17:15 2014 +0900
commit1
Rebase
- Exec this (number 2 means how many commits to be one commit):
git rebase -i HEAD~2
- Editor launches with this text:
pick 2447554 commit1 pick 50e8dee commit2 # Rebase 9ccae64..50e8dee onto 9ccae64 # # Commands: # p, pick = use commit # r, reword = use commit, but edit the commit message # e, edit = use commit, but stop for amending # s, squash = use commit, but meld into previous commit # f, fixup = like "squash", but discard this commit's log message # x, exec = run command (the rest of the line) using shell # # These lines can be re-ordered; they are executed from top to bottom. # # If you remove a line here THAT COMMIT WILL BE LOST. # # However, if you remove everything, the rebase will be aborted. # # Note that empty commits are commented out
- Edit to:
pick 2447554 commit1 squash 50e8dee commit2
- Another editor will launch so that we can edit commit message:
# This is a combination of 2 commits. # The first commit's message is: commit1 # This is the 2nd commit message: commit2 # Please enter the commit message for your changes. Lines starting # with '#' will be ignored, and an empty message aborts the commit. # HEAD detached at 2447554 # You are currently editing a commit while rebasing branch 'b4' on '9ccae64'. # # Changes to be committed: # (use "git reset HEAD^1 <file>..." to unstage) # # modified: README.md #
- Gone like this:
kyle-no-MacBook:hello kyle$ git rebase -i HEAD~2 [detached HEAD ada1147] commit1 1 file changed, 2 insertions(+) Successfully rebased and updated refs/heads/b4. kyle-no-MacBook:hello kyle$
- Log:
kyle-no-MacBook:hello kyle$ git log -2
commit ada114798c5727e8461afc36a10ad0b36e5e214a
Author: lbtc-xxx <lbtc-xxx@example.com>
Date: Sun Mar 9 20:17:15 2014 +0900
commit1
commit2
commit 9ccae643e8ceee10c5f7bcb4103857bc1a38cdd4
Author: lbtc-xxx <lbtc-xxx@example.com>
Date: Sun Mar 9 19:09:56 2014 +0900
cancel
kyle-no-MacBook:hello kyle$
- README.md
kyle-no-MacBook:hello kyle$ cat README.md b4-local1 CANCEL commit1 commit2 kyle-no-MacBook:hello kyle$
Tags: git
Cancelling commit and push
TweetPosted on Sunday Mar 09, 2014 at 05:17PM in Technology
Cancel a commit
kyle-no-MacBook:hello kyle$ echo CANCEL >> README.md kyle-no-MacBook:hello kyle$ git commit -am 'cancel' [b4 8c2027b] cancel 1 file changed, 1 insertion(+) kyle-no-MacBook:hello kyle$
- Cancel:
kyle-no-MacBook:hello kyle$ git reset HEAD^
Unstaged changes after reset:
M README.md
kyle-no-MacBook:hello kyle$ git status
# On branch b4
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: README.md
#
no changes added to commit (use "git add" and/or "git commit -a")
kyle-no-MacBook:hello kyle$ git log
commit 75dc62abde6e533a5aef8ecab248ed4f3bbfe43a
Author: lbtc-xxx <lbtc-xxx@example.com>
Date: Sun Mar 9 17:40:57 2014 +0900
local1-b4
- If you want to commit again, just do this:
git commit -am 'cancel'
Cancel a push
kyle-no-MacBook:hello kyle$ git push warning: push.default is unset; its implicit value is changing in ... Counting objects: 10, done. Delta compression using up to 8 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (6/6), 498 bytes | 0 bytes/s, done. Total 6 (delta 1), reused 0 (delta 0) To git@github.com:lbtc-xxx/hello.git bdbe00c..c107ca9 b1 -> b1 75dc62a..9ccae64 b4 -> b4 059de38..30254fe master -> master kyle-no-MacBook:hello kyle$
- Now b4 is:
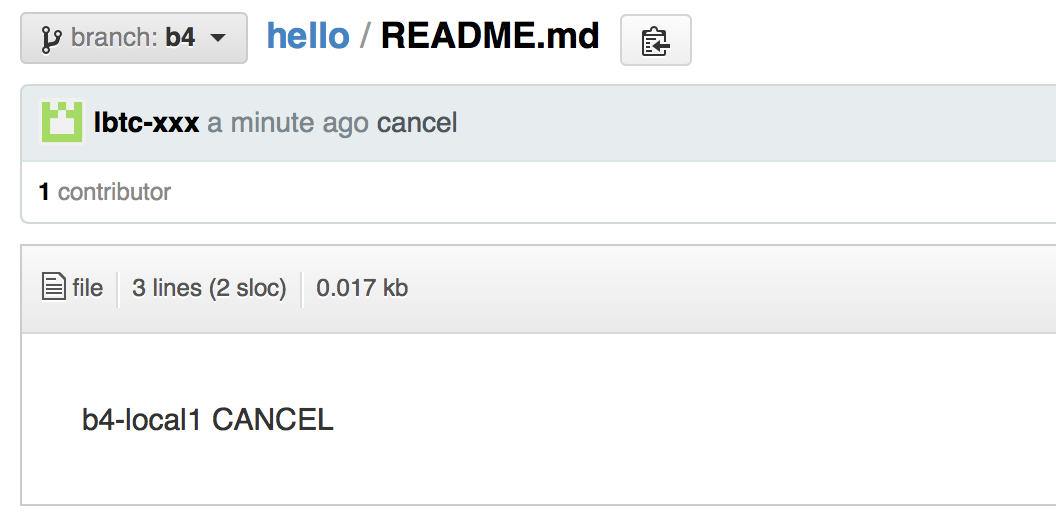
- Cancelling:
kyle-no-MacBook:hello kyle$ git push -f origin HEAD^:b4 Total 0 (delta 0), reused 0 (delta 0) To git@github.com:lbtc-xxx/hello.git + 9ccae64...75dc62a HEAD^ -> b4 (forced update) kyle-no-MacBook:hello kyle$
- Roll-backed:
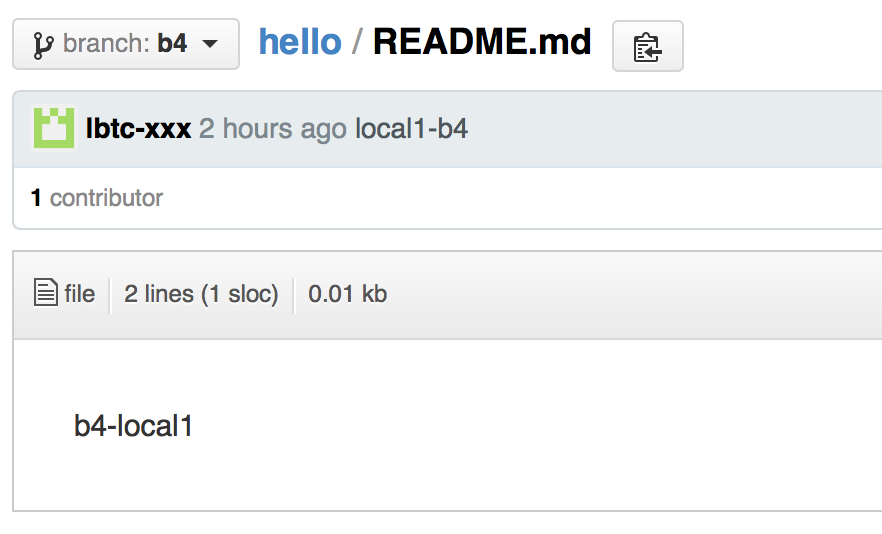
References
Tags: git
