WildFly8でPostgreSQLをジョブレポジトリにしてみる
TweetPosted on Thursday Feb 13, 2014 at 07:26AM in Technology
WildFly8でJDBCジョブレポジトリを使ってみるでH2を使ってやってみたけど、PostgreSQLでやってみると、XAデータソースとかではまったのでメモしておく
環境
- WildFly8.0.0.Final
- postgresql-9.3-1100.jdbc41.jar
- Oracle JDK7u51
- PostgreSQL 9.2.4
- OS X 10.9.1
postgresql.confを編集する
max_prepared_transactionsを増やす
デフォルトだと、バッチ実行時にこういう例外が出て死ぬ。
10:56:53,218 WARN [com.arjuna.ats.jta] (batch-batch - 1) ARJUNA016041: prepare on < formatId=131077, gtrid_length=29, bqual_length=36, tx_uid=0:ffff0a00010b:-79718ed6:52fc262f:17, node_name=1, branch_uid=0:ffff0a00010b:-79718ed6:52fc262f:1b, subordinatenodename=null, eis_name=java:jboss/jdbc/JBatchDS > (XAResourceWrapperImpl@4a5bf320[xaResource=org.jboss.jca.adapters.jdbc.xa.XAManagedConnection@3c38e6e8 pad=false overrideRmValue=null productName=PostgreSQL productVersion=9.2.4 jndiName=java:jboss/jdbc/JBatchDS]) failed with exception XAException.XAER_RMERR: org.postgresql.xa.PGXAException: トランザクションの準備エラー
at org.postgresql.xa.PGXAConnection.prepare(PGXAConnection.java:313)
at org.jboss.jca.adapters.jdbc.xa.XAManagedConnection.prepare(XAManagedConnection.java:330)
at org.jboss.jca.core.tx.jbossts.XAResourceWrapperImpl.prepare(XAResourceWrapperImpl.java:169)
at com.arjuna.ats.internal.jta.resources.arjunacore.XAResourceRecord.topLevelPrepare(XAResourceRecord.java:210) [narayana-jts-jacorb-5.0.0.Final.jar:5.0.0.Final (revision: 9aa71)]
at com.arjuna.ats.arjuna.coordinator.BasicAction.doPrepare(BasicAction.java:2586) [narayana-jts-jacorb-5.0.0.Final.jar:5.0.0.Final (revision: 9aa71)]
at com.arjuna.ats.arjuna.coordinator.BasicAction.doPrepare(BasicAction.java:2536) [narayana-jts-jacorb-5.0.0.Final.jar:5.0.0.Final (revision: 9aa71)]
at com.arjuna.ats.arjuna.coordinator.BasicAction.prepare(BasicAction.java:2097) [narayana-jts-jacorb-5.0.0.Final.jar:5.0.0.Final (revision: 9aa71)]
at com.arjuna.ats.arjuna.coordinator.BasicAction.End(BasicAction.java:1481) [narayana-jts-jacorb-5.0.0.Final.jar:5.0.0.Final (revision: 9aa71)]
at com.arjuna.ats.arjuna.coordinator.TwoPhaseCoordinator.end(TwoPhaseCoordinator.java:96) [narayana-jts-jacorb-5.0.0.Final.jar:5.0.0.Final (revision: 9aa71)]
at com.arjuna.ats.arjuna.AtomicAction.commit(AtomicAction.java:162) [narayana-jts-jacorb-5.0.0.Final.jar:5.0.0.Final (revision: 9aa71)]
at com.arjuna.ats.internal.jta.transaction.arjunacore.TransactionImple.commitAndDisassociate(TransactionImple.java:1166) [narayana-jts-jacorb-5.0.0.Final.jar:5.0.0.Final (revision: 9aa71)]
at com.arjuna.ats.internal.jta.transaction.arjunacore.BaseTransaction.commit(BaseTransaction.java:126) [narayana-jts-jacorb-5.0.0.Final.jar:5.0.0.Final (revision: 9aa71)]
at com.arjuna.ats.jbossatx.BaseTransactionManagerDelegate.commit(BaseTransactionManagerDelegate.java:75)
at org.jberet.runtime.runner.ChunkRunner.readProcessWriteItems(ChunkRunner.java:323) [jberet-core-1.0.0.Final.jar:1.0.0.Final]
at org.jberet.runtime.runner.ChunkRunner.run(ChunkRunner.java:193) [jberet-core-1.0.0.Final.jar:1.0.0.Final]
at org.jberet.runtime.runner.StepExecutionRunner.runBatchletOrChunk(StepExecutionRunner.java:204) [jberet-core-1.0.0.Final.jar:1.0.0.Final]
at org.jberet.runtime.runner.StepExecutionRunner.run(StepExecutionRunner.java:131) [jberet-core-1.0.0.Final.jar:1.0.0.Final]
at org.jberet.runtime.runner.CompositeExecutionRunner.runStep(CompositeExecutionRunner.java:162) [jberet-core-1.0.0.Final.jar:1.0.0.Final]
at org.jberet.runtime.runner.CompositeExecutionRunner.runFromHeadOrRestartPoint(CompositeExecutionRunner.java:88) [jberet-core-1.0.0.Final.jar:1.0.0.Final]
at org.jberet.runtime.runner.JobExecutionRunner.run(JobExecutionRunner.java:58) [jberet-core-1.0.0.Final.jar:1.0.0.Final]
at org.wildfly.jberet.services.BatchEnvironmentService$WildFlyBatchEnvironment$1.run(BatchEnvironmentService.java:149) [wildfly-jberet-8.0.0.Final.jar:8.0.0.Final]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) [rt.jar:1.7.0_51]
at java.util.concurrent.FutureTask.run(FutureTask.java:262) [rt.jar:1.7.0_51]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) [rt.jar:1.7.0_51]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) [rt.jar:1.7.0_51]
at java.lang.Thread.run(Thread.java:744) [rt.jar:1.7.0_51]
at org.jboss.threads.JBossThread.run(JBossThread.java:122)
Caused by: org.postgresql.util.PSQLException: ERROR: prepared transactions are disabled
ヒント: Set max_prepared_transactions to a nonzero value.
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2161)
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:1890)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:255)
at org.postgresql.jdbc2.AbstractJdbc2Statement.execute(AbstractJdbc2Statement.java:560)
at org.postgresql.jdbc2.AbstractJdbc2Statement.executeWithFlags(AbstractJdbc2Statement.java:403)
at org.postgresql.jdbc2.AbstractJdbc2Statement.executeUpdate(AbstractJdbc2Statement.java:331)
at org.postgresql.xa.PGXAConnection.prepare(PGXAConnection.java:301)
... 26 more
[4]によると、何やらpostgresql.confの設定を変更せねばならんらしい。デフォルトが0で無効になっているらしい[5]。
#max_prepared_transactions = 0 # zero disables the feature
# (change requires restart)
とりあえず20に増やすとOKっぽい
max_prepared_transactions = 20 # zero disables the feature
100にしてみたら、こんな感じで起動しなかった。何か設定が必要なのだろう
Feb 13 11:17:30 kyle-no-MacBook.local postgres[23553]: [1-1] 2014-02-13 11:17:30 JST FATAL: could not create shared memory segment: Invalid argument Feb 13 11:17:30 kyle-no-MacBook.local postgres[23553]: [1-2] 2014-02-13 11:17:30 JST DETAIL: Failed system call was shmget(key=5432001, size=36937728, 03600). Feb 13 11:17:30 kyle-no-MacBook.local postgres[23553]: [1-3] 2014-02-13 11:17:30 JST HINT: This error usually means that PostgreSQL's request for a shared memory segment exceeded your kernel's SHMMAX parameter. You can either reduce the request size or reconfigure the kernel with larger SHMMAX. To reduce the request size (currently 36937728 bytes), reduce PostgreSQL's shared memory usage, perhaps by reducing shared_buffers or max_connections. Feb 13 11:17:30 kyle-no-MacBook.local postgres[23553]: [1-4] If the request size is already small, it's possible that it is less than your kernel's SHMMIN parameter, in which case raising the request size or reconfiguring SHMMIN is called for. Feb 13 11:17:30 kyle-no-MacBook.local postgres[23553]: [1-5] The PostgreSQL documentation contains more information about shared memory configuration.
再起動
sudo launchctl stop com.edb.launchd.postgresql-9.2 sudo launchctl start com.edb.launchd.postgresql-9.2
ジョブレポジトリ用のXAデータソースを定義する
jboss-cliを使う。こういう感じ
batch
xa-data-source add \
--name=JBatchDS \
--driver-name=postgresql \
--jndi-name=java:jboss/jdbc/JBatchDS \
--user-name=postgres \
--password=***
/subsystem=datasources/xa-data-source="JBatchDS"/xa-datasource-properties=ServerName:add(value="localhost")
/subsystem=datasources/xa-data-source="JBatchDS"/xa-datasource-properties=PortNumber:add(value="5432")
/subsystem=datasources/xa-data-source="JBatchDS"/xa-datasource-properties=DatabaseName:add(value="jbatch")
run-batch
接続テストとかその他のデータソース関連操作はWildFly - CLIでデータソースを定義するに書いたのも何かの参考になるかも
アプリ用のXAデータソースを定義する
アプリ用の方は普通のデータソースでもよいのかしら?わからん。ジョブレポジトリ用と同じ感じです。
ジョブレポジトリを変更
WildFly8でJDBCジョブレポジトリを使ってみるで書いたのと同じ感じなので省略。
バッチを動かしてみる
Chunk方式のStepを使ってみるで作ったバッチを動かしてみると、Repository用のDDLが勝手に流されて必要なテーブルやシーケンスを勝手に作ってくれる。ログを見ているとこういうのが流れている
2014-02-13 09:57:02,584 INFO [org.jberet] (pool-2-thread-1) JBERET000021: About to initialize batch job repository with ddl-file: sql/jberet-postgresql.ddl for database PostgreSQL
Repositoryのテーブル一覧を見てみる
jbatch=# \d
List of relations
Schema | Name | Type | Owner
--------+------------------------------------+----------+----------
public | job_execution | table | postgres
public | job_execution_jobexecutionid_seq | sequence | postgres
public | job_instance | table | postgres
public | job_instance_jobinstanceid_seq | sequence | postgres
public | partition_execution | table | postgres
public | step_execution | table | postgres
public | step_execution_stepexecutionid_seq | sequence | postgres
(7 rows)
jbatch=#
Repositoryのテーブルに入っているレコードも見てみる
FAILEDになっているのはXAデータソースがらみではまって死んだところ。いろいろと設定を加えて再実行した結果COMPLETEDが1件できた
jbatch=# select * from job_execution;
jobexecutionid | jobinstanceid | version | createtime | starttime | endtime | lastupdatedtime | batchstatus | exitstatus | jobparameters | restartposition
----------------+---------------+---------+-------------------------+-------------------------+-------------------------+-------------------------+-------------+------------+---------------+-----------------
1 | 1 | | 2014-02-13 09:57:02.685 | 2014-02-13 09:57:02.685 | 2014-02-13 09:57:02.999 | 2014-02-13 09:57:02.999 | FAILED | FAILED | divide = 2 +|
| | | | | | | | | |
2 | 2 | | 2014-02-13 09:58:59.033 | 2014-02-13 09:58:59.033 | 2014-02-13 09:58:59.058 | 2014-02-13 09:58:59.058 | FAILED | FAILED | divide = 2 +|
| | | | | | | | | |
3 | 3 | | 2014-02-13 10:01:44.972 | 2014-02-13 10:01:44.972 | 2014-02-13 10:01:44.994 | 2014-02-13 10:01:44.994 | FAILED | FAILED | divide = 2 +|
| | | | | | | | | |
4 | 4 | | 2014-02-13 10:56:52.962 | 2014-02-13 10:56:52.962 | 2014-02-13 10:56:53.231 | 2014-02-13 10:56:53.231 | FAILED | FAILED | divide = 2 +|
| | | | | | | | | |
5 | 5 | | 2014-02-13 11:18:51.947 | 2014-02-13 11:18:51.947 | 2014-02-13 11:18:52.28 | 2014-02-13 11:18:52.28 | COMPLETED | COMPLETED | divide = 2 +|
| | | | | | | | | |
(5 rows)
jbatch=# select * from job_instance;
jobinstanceid | version | jobname | applicationname
---------------+---------+---------+-----------------
1 | | chunk | jbatchtest
2 | | chunk | jbatchtest
3 | | chunk | jbatchtest
4 | | chunk | jbatchtest
5 | | chunk | jbatchtest
(5 rows)
jbatch=# select * from step_execution;
stepexecutionid | jobexecutionid | version | stepname | starttime | endtime | batchstatus | exitstatus | executionexception | persistentuserdata | readcount | writecount | commitcount | rollbackcount | readskipcount | processskipcount | filtercount | writeskipcount | readercheckpointinfo | writercheckpointinfo
-----------------+----------------+---------+----------+-------------------------+-------------------------+-------------+------------+--------------------+--------------------+-----------+------------+-------------+---------------+---------------+------------------+-------------+----------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | 1 | | doChunk | 2014-02-13 09:57:02.726 | | STARTED | | | | | | | | | | | | |
2 | 2 | | doChunk | 2014-02-13 09:58:59.036 | | STARTED | | | | | | | | | | | | |
3 | 3 | | doChunk | 2014-02-13 10:01:44.974 | | STARTED | | | | | | | | | | | | |
4 | 4 | | doChunk | 2014-02-13 10:56:52.98 | | STARTED | | | | | | | | | | | | |
5 | 5 | | doChunk | 2014-02-13 11:18:51.965 | 2014-02-13 11:18:52.276 | COMPLETED | COMPLETED | | | 10 | 10 | 4 | 0 | 0 | 0 | 0 | 0 | \xaced0005737200116a6176612e6c616e672e496e746567657212e2a0a4f781873802000149000576616c7565787200106a6176612e6c616e672e4e756d62657286ac951d0b94e08b02000078700000000a | \xaced0005737200116a6176612e6c616e672e496e746567657212e2a0a4f781873802000149000576616c7565787200106a6176612e6c616e672e4e756d62657286ac951d0b94e08b020000787000000004
(5 rows)
jbatch=# select * from partition_execution ;
partitionexecutionid | stepexecutionid | version | batchstatus | exitstatus | executionexception | persistentuserdata | readercheckpointinfo | writercheckpointinfo
----------------------+-----------------+---------+-------------+------------+--------------------+--------------------+----------------------+----------------------
(0 rows)
jbatch=#
アプリのテーブルを見てみる
まあ普通
jbatch=# \c jbatcharts You are now connected to database "jbatcharts" as user "kyle". jbatcharts=# select * from chunkoutputitem ; id | result ----+-------- 0 | 0 1 | 5 2 | 10 3 | 15 4 | 20 5 | 25 6 | 30 7 | 35 8 | 40 9 | 45 (10 rows) jbatcharts=#
備考
勝手に作られるRepositoryにはインデックスがほとんどないので、履歴が増えてきたときに備えていくつか作っておいたほうが良いような気もする。
参考文献
Tags: jbatch
Chunk方式のStepでJDBCを使ってみる
TweetPosted on Thursday Feb 13, 2014 at 07:25AM in Technology
Chunk方式のStepを使ってみるではJPAだったが、同じ事をJDBCでやってみる。一応大量のデータを想定した感じに作ってみる。実際に大量のデータでの実験はしてないけど。
JSR 352 Implementation - Connection close probl… | Communityによると、ここに書いてあるような実装はよろしくないようです。SELECT文の発行などは全て同一トランザクション内で完結する必要があるらしい。open()で取得するのはPKだけにして、実際のデータはreadItem()で別途取得するようにするなどした方が良いかも
トランザクション境界を跨いでJDBCの資源(Connection, Statement, ResultSet等)を使う場合は,非JTAデータソースを使いましょう.詳細はこちらを参照.また,このエントリで出している例のようにopen()でConnection, PreparedStatementを作るのはよろしくないようです.writeItems()内で,つどつど作りましょう.
環境・前提条件
Chunk方式のStepを使ってみると同じ。この記事で作ったプロジェクトや資源がすでに存在するものとする
準備
- 資源の詳細はこのあたり
- エンティティ、テストデータは流用する
- @ResourceでDataSourceを注入するのでweb.xmlとjboss-web.xmlを置いてある
バッチを構成する資源
chunkjdbc.xml
- ジョブXML。artifact以外は前回と同じ
ChunkJDBCItemReader.java
- SELECT文でOFFSET使ってるのでPostgreSQL以外の場合は適当に変えてやる
ChunkJDBCItemProcessor.java
- 一応コピーして作ったけど完全に前回と同じ
- DTO作るのが面倒ならResultSetを受け取ってもよかったかも
ChunkJDBCItemWriter.java
- PreparedStatement#addBatch()とexecuteBatch()を使ってみた
- この例は誤っていて,open()でConnection, PreparedStatementを作るのはよろしくないようです.writeItems()内で,つどつど作りましょう.
テスト用資源
ChunkJDBCJobTest.java
- テストクラス。ジョブの名前以外前回と同じ
実行してみる
ログはこんな感じ。実行結果もテーブル出力も特に問題なさげ
14:41:53,140 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemProcessor] (batch-batch - 7) postConstruct(): divide=2 14:41:53,140 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) open(): checkpoint=null, index starts at=0 14:41:53,142 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) open(): checkpoint=null, index starts at=0 14:41:53,142 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): index=0 14:41:53,143 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): returning=ChunkInputItem [id=0, input=0, processed=false] 14:41:53,143 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemProcessor] (batch-batch - 7) processItem(): input=ChunkInputItem [id=0, input=0, processed=false], output=ChunkOutputItem [id=0, result=0] 14:41:53,143 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=1 14:41:53,143 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): index=1 14:41:53,143 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): returning=ChunkInputItem [id=1, input=10, processed=false] 14:41:53,143 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemProcessor] (batch-batch - 7) processItem(): input=ChunkInputItem [id=1, input=10, processed=false], output=ChunkOutputItem [id=1, result=5] 14:41:53,143 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=2 14:41:53,143 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): index=2 14:41:53,143 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): returning=ChunkInputItem [id=2, input=20, processed=false] 14:41:53,144 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemProcessor] (batch-batch - 7) processItem(): input=ChunkInputItem [id=2, input=20, processed=false], output=ChunkOutputItem [id=2, result=10] 14:41:53,144 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=3 14:41:53,144 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): index=0 14:41:53,144 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): item=ChunkOutputItem [id=0, result=0] 14:41:53,144 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): item=ChunkOutputItem [id=1, result=5] 14:41:53,144 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): item=ChunkOutputItem [id=2, result=10] 14:41:53,151 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): ps#executeBatch() result=1 14:41:53,152 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): ps#executeBatch() result=1 14:41:53,152 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): ps#executeBatch() result=1 14:41:53,152 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=3 14:41:53,152 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) checkpointInfo(): returns=1 14:41:53,154 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=3 14:41:53,160 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): index=3 14:41:53,160 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): returning=ChunkInputItem [id=3, input=30, processed=false] 14:41:53,160 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemProcessor] (batch-batch - 7) processItem(): input=ChunkInputItem [id=3, input=30, processed=false], output=ChunkOutputItem [id=3, result=15] 14:41:53,161 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=4 14:41:53,161 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): index=4 14:41:53,161 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): returning=ChunkInputItem [id=4, input=40, processed=false] 14:41:53,161 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemProcessor] (batch-batch - 7) processItem(): input=ChunkInputItem [id=4, input=40, processed=false], output=ChunkOutputItem [id=4, result=20] 14:41:53,161 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=5 14:41:53,161 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): index=5 14:41:53,161 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): returning=ChunkInputItem [id=5, input=50, processed=false] 14:41:53,161 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemProcessor] (batch-batch - 7) processItem(): input=ChunkInputItem [id=5, input=50, processed=false], output=ChunkOutputItem [id=5, result=25] 14:41:53,161 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=6 14:41:53,161 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): index=1 14:41:53,161 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): item=ChunkOutputItem [id=3, result=15] 14:41:53,162 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): item=ChunkOutputItem [id=4, result=20] 14:41:53,162 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): item=ChunkOutputItem [id=5, result=25] 14:41:53,168 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): ps#executeBatch() result=1 14:41:53,168 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): ps#executeBatch() result=1 14:41:53,168 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): ps#executeBatch() result=1 14:41:53,168 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=6 14:41:53,169 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) checkpointInfo(): returns=2 14:41:53,170 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=6 14:41:53,171 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): index=6 14:41:53,171 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): returning=ChunkInputItem [id=6, input=60, processed=false] 14:41:53,171 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemProcessor] (batch-batch - 7) processItem(): input=ChunkInputItem [id=6, input=60, processed=false], output=ChunkOutputItem [id=6, result=30] 14:41:53,171 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=7 14:41:53,171 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): index=7 14:41:53,171 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): returning=ChunkInputItem [id=7, input=70, processed=false] 14:41:53,171 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemProcessor] (batch-batch - 7) processItem(): input=ChunkInputItem [id=7, input=70, processed=false], output=ChunkOutputItem [id=7, result=35] 14:41:53,171 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=8 14:41:53,171 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): index=8 14:41:53,171 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): returning=ChunkInputItem [id=8, input=80, processed=false] 14:41:53,171 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemProcessor] (batch-batch - 7) processItem(): input=ChunkInputItem [id=8, input=80, processed=false], output=ChunkOutputItem [id=8, result=40] 14:41:53,172 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=9 14:41:53,172 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): index=2 14:41:53,172 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): item=ChunkOutputItem [id=6, result=30] 14:41:53,172 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): item=ChunkOutputItem [id=7, result=35] 14:41:53,172 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): item=ChunkOutputItem [id=8, result=40] 14:41:53,173 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): ps#executeBatch() result=1 14:41:53,173 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): ps#executeBatch() result=1 14:41:53,173 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): ps#executeBatch() result=1 14:41:53,173 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=9 14:41:53,173 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) checkpointInfo(): returns=3 14:41:53,174 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=9 14:41:53,175 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): index=9 14:41:53,175 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): returning=ChunkInputItem [id=9, input=90, processed=false] 14:41:53,175 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemProcessor] (batch-batch - 7) processItem(): input=ChunkInputItem [id=9, input=90, processed=false], output=ChunkOutputItem [id=9, result=45] 14:41:53,175 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=10 14:41:53,175 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): index=10 14:41:53,175 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) readItem(): returning=null 14:41:53,175 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): index=3 14:41:53,175 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): item=ChunkOutputItem [id=9, result=45] 14:41:53,176 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) writeItems(): ps#executeBatch() result=1 14:41:53,176 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=10 14:41:53,176 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) checkpointInfo(): returns=4 14:41:53,177 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) checkpointInfo(): returns=10 14:41:53,178 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) close() 14:41:53,178 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) close() 14:41:53,178 WARN [com.arjuna.ats.jta] (batch-batch - 7) ARJUNA016087: TransactionImple.delistResource - unknown resource 14:41:53,178 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemReader] (batch-batch - 7) close() 14:41:53,178 FINE [org.nailedtothex.jbatch.example.chunkjdbc.ChunkJDBCItemWriter] (batch-batch - 7) close()
備考
- 定型コードが多い。SQL文とバインド変数を外出しすれば、かなり共通化できるような気もするが…。CDIをうまく使えばなんとかなりそうな気もするけど。そのうちまたいろいろ試してみる。
- closeするところはDbUtils.closeQuietly()使えばちょっと楽になりそう
参考文献
Tags: jbatch
GitHubのプロジェクトをインポートしてみる
TweetPosted on Tuesday Feb 11, 2014 at 03:13PM in Technology
GitHubにプロジェクトを上げてみるでpushしたプロジェクトをEclipseでImportしてみる
環境
- Eclipse Kepler SR1
準備
- 手元の端末にある資源を削除しておく
手順
[1]と殆ど同じ。もはやただの記録
File→Import
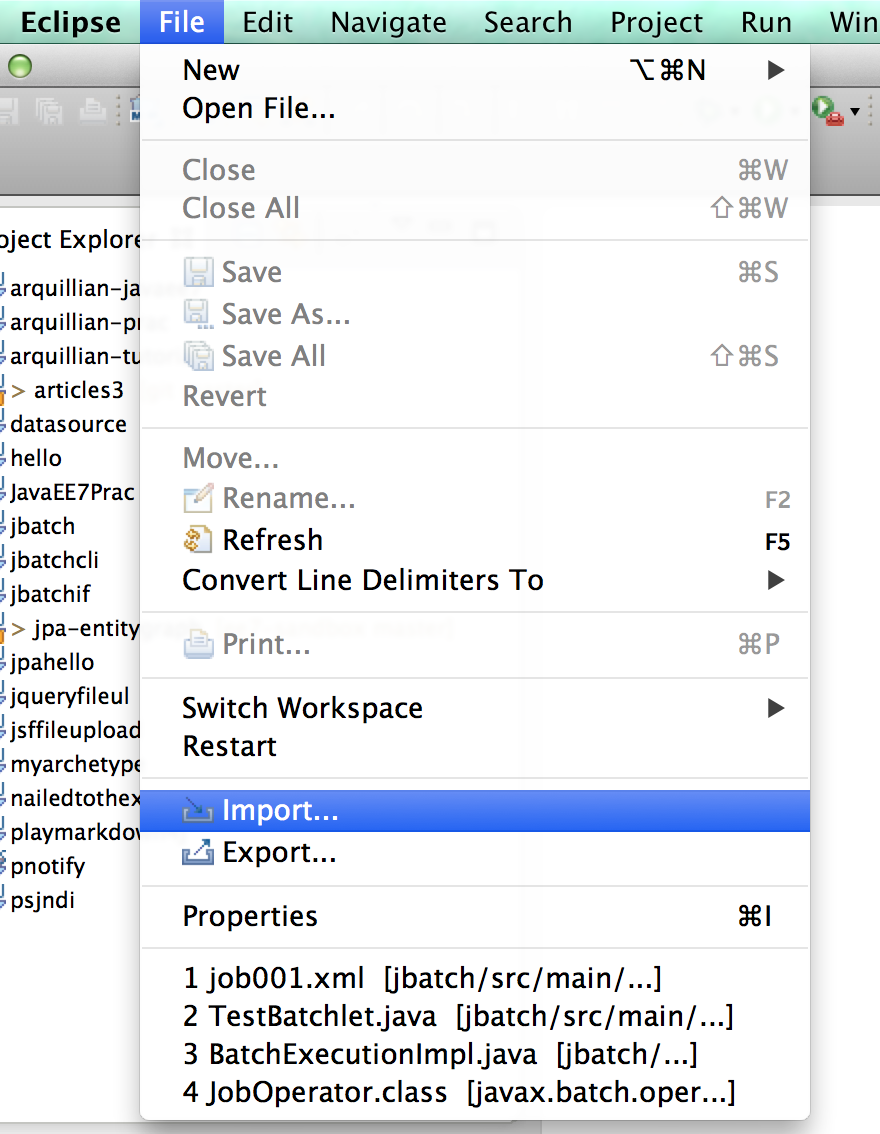
Projects from Gitを選んでNext
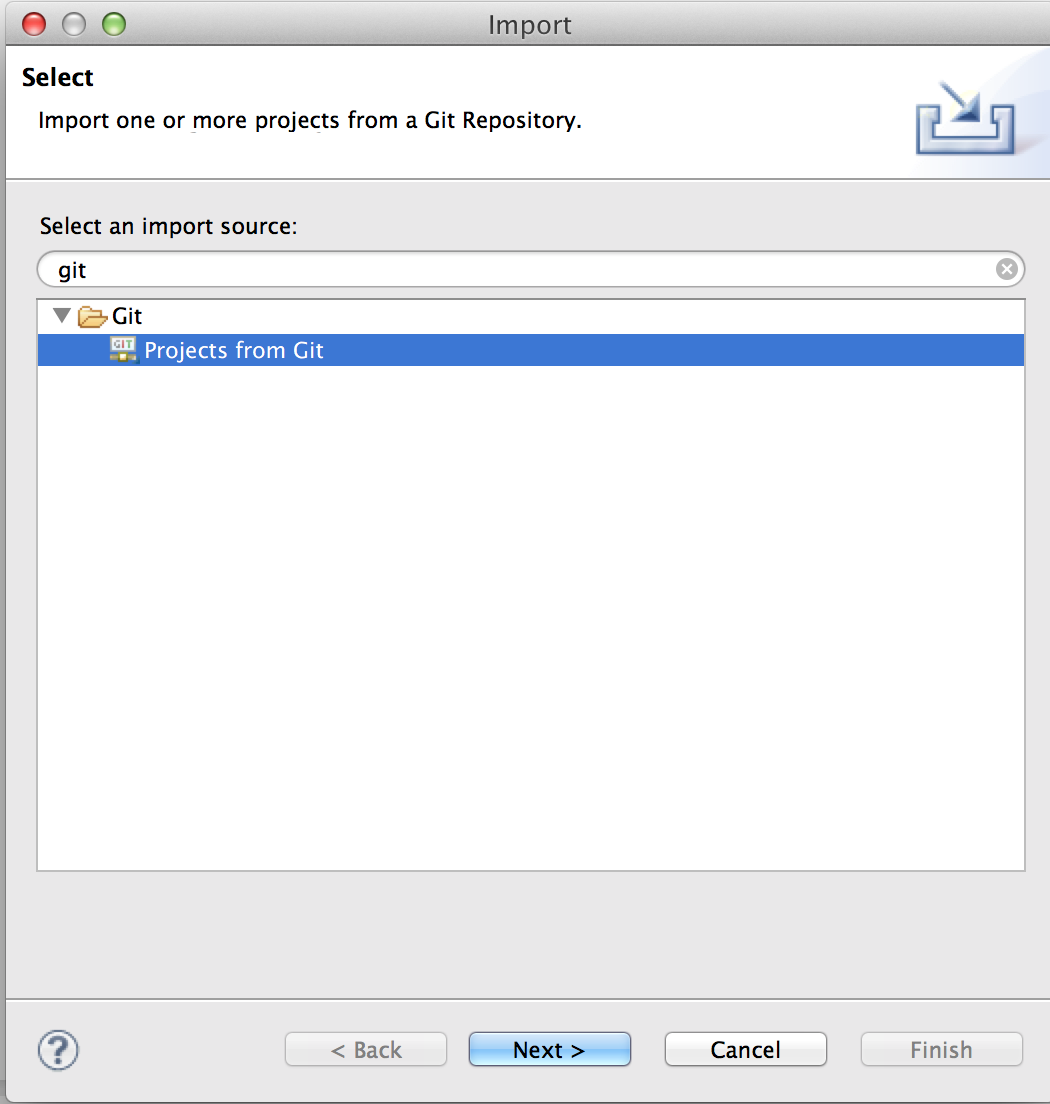
Clone URIを選んでNext
GitHubのRepositoryの画面からURLをコピーしてくる。ここのクリップボード的なボタンを押すとコピーされる
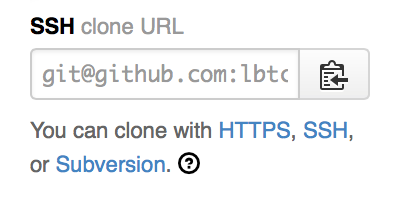
URIに貼付けてNext
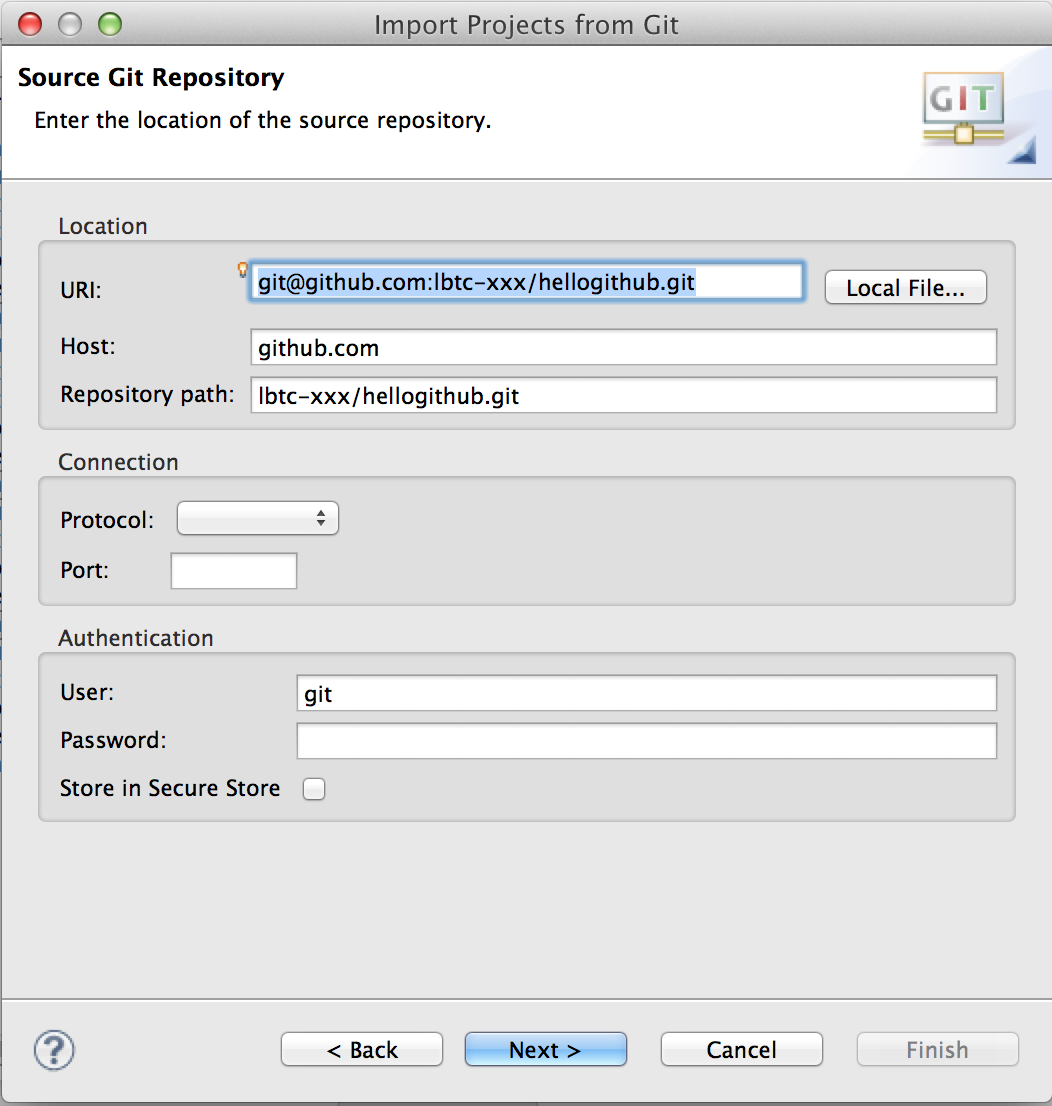
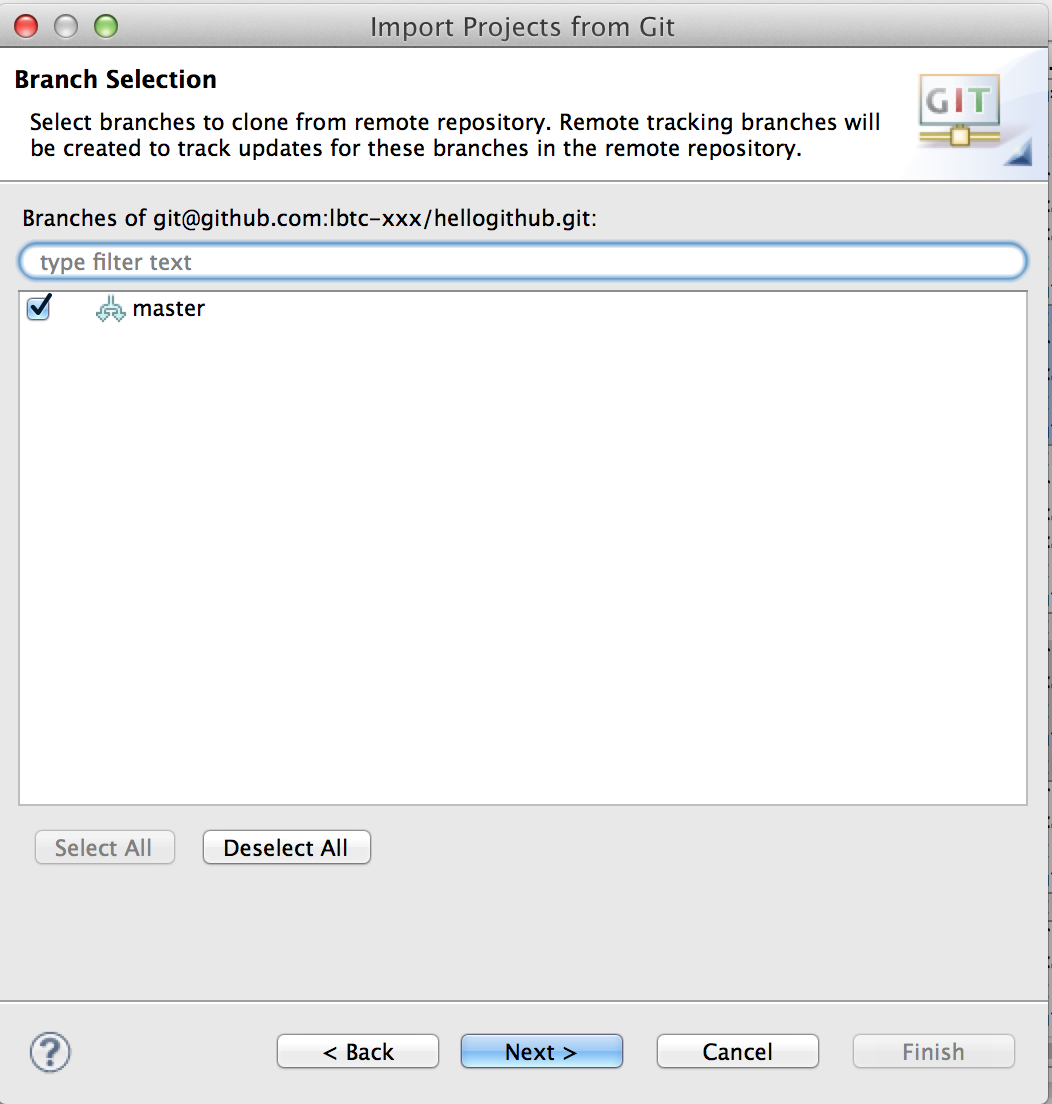
Next
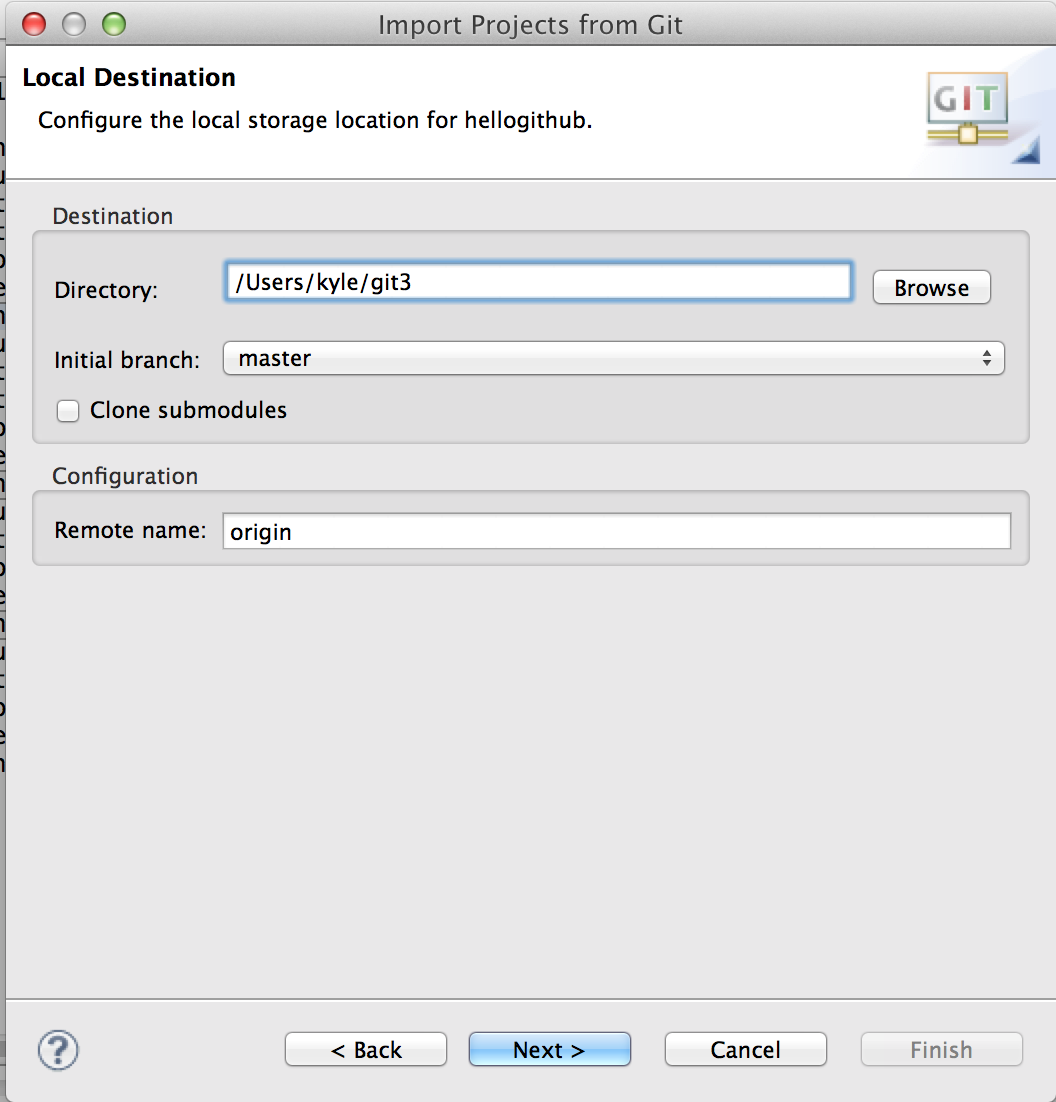
ローカルの資源の置き場所を入力してNext
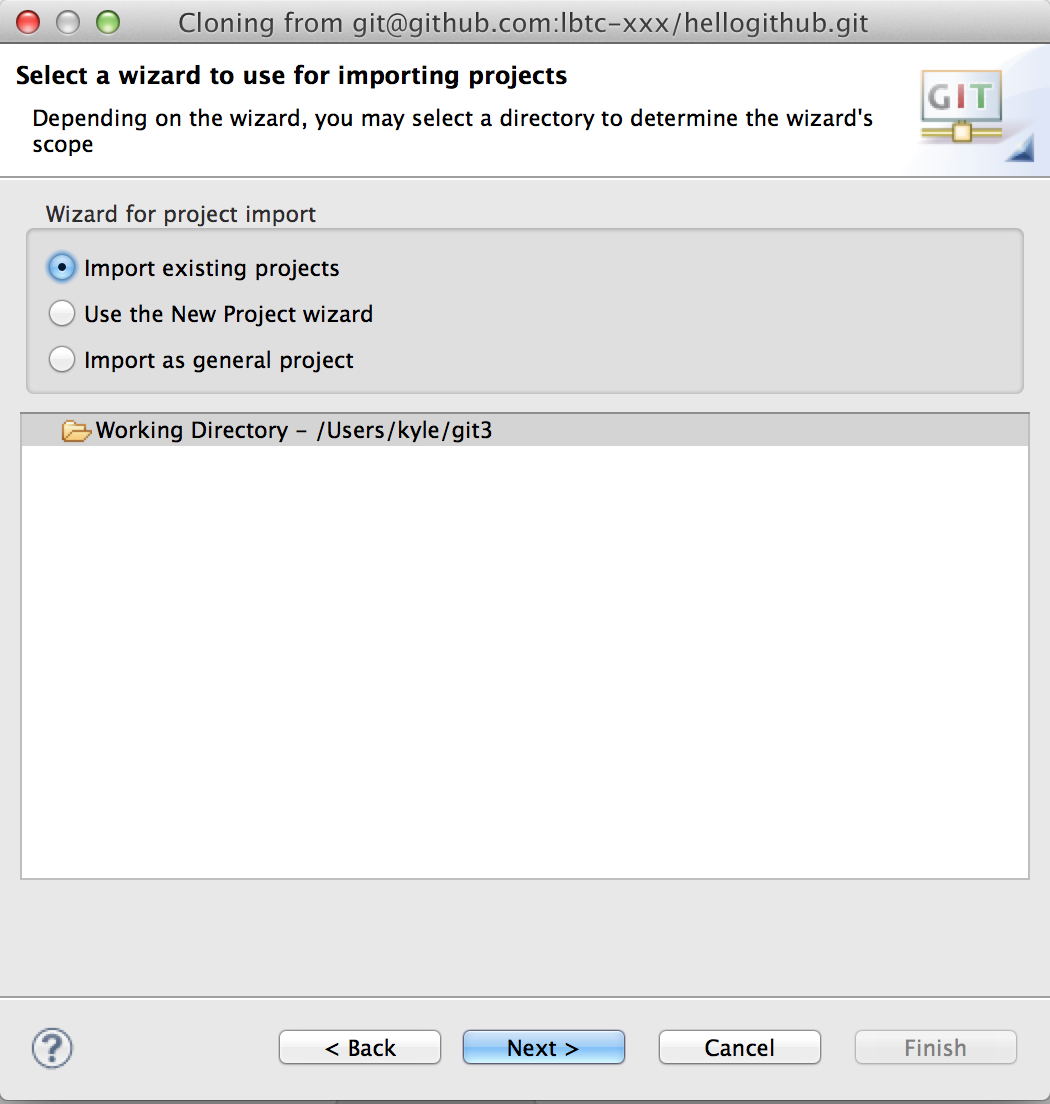
Import exisiting projectsを選んでNext
Finish
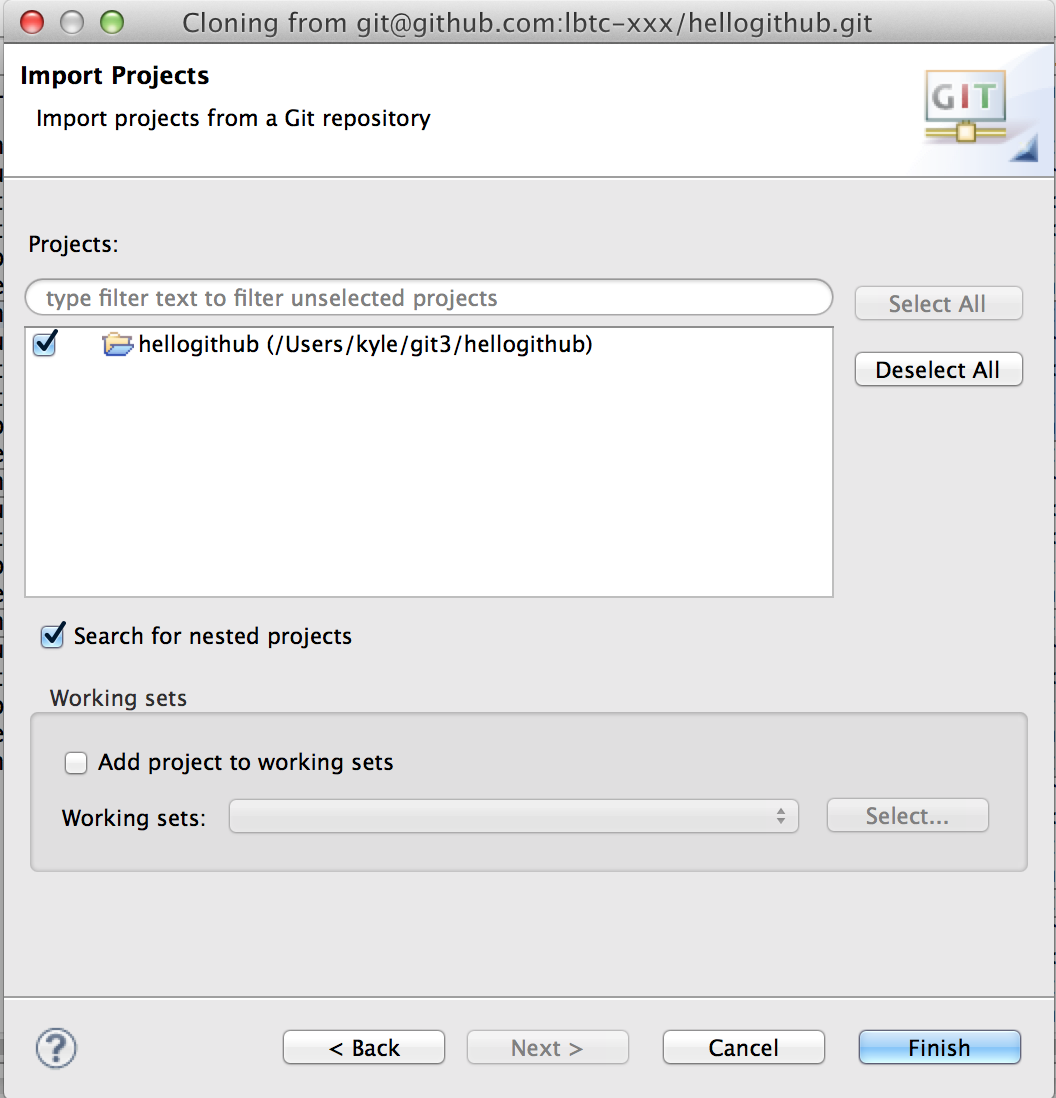
インポートしたプロジェクトが現れる
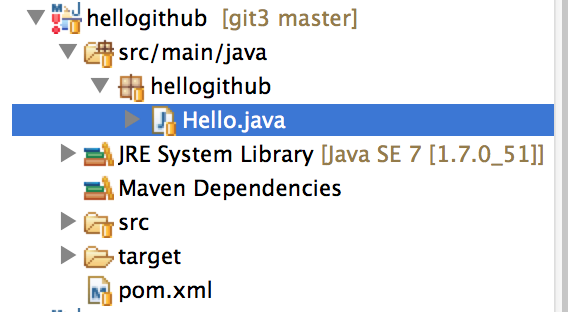
空のフォルダを作る
エラー的なものが出ている。どうやら空のフォルダがgitに上がってないようだ。
ゆえに手作業で作る。何か間違っているような気もするが。
kyle-no-MacBook:git3 kyle$ mkdir -p hellogithub/src/main/resources kyle-no-MacBook:git3 kyle$ mkdir -p hellogithub/src/test/java kyle-no-MacBook:git3 kyle$ mkdir -p hellogithub/src/test/resources
作ったらプロジェクトをリフレッシュ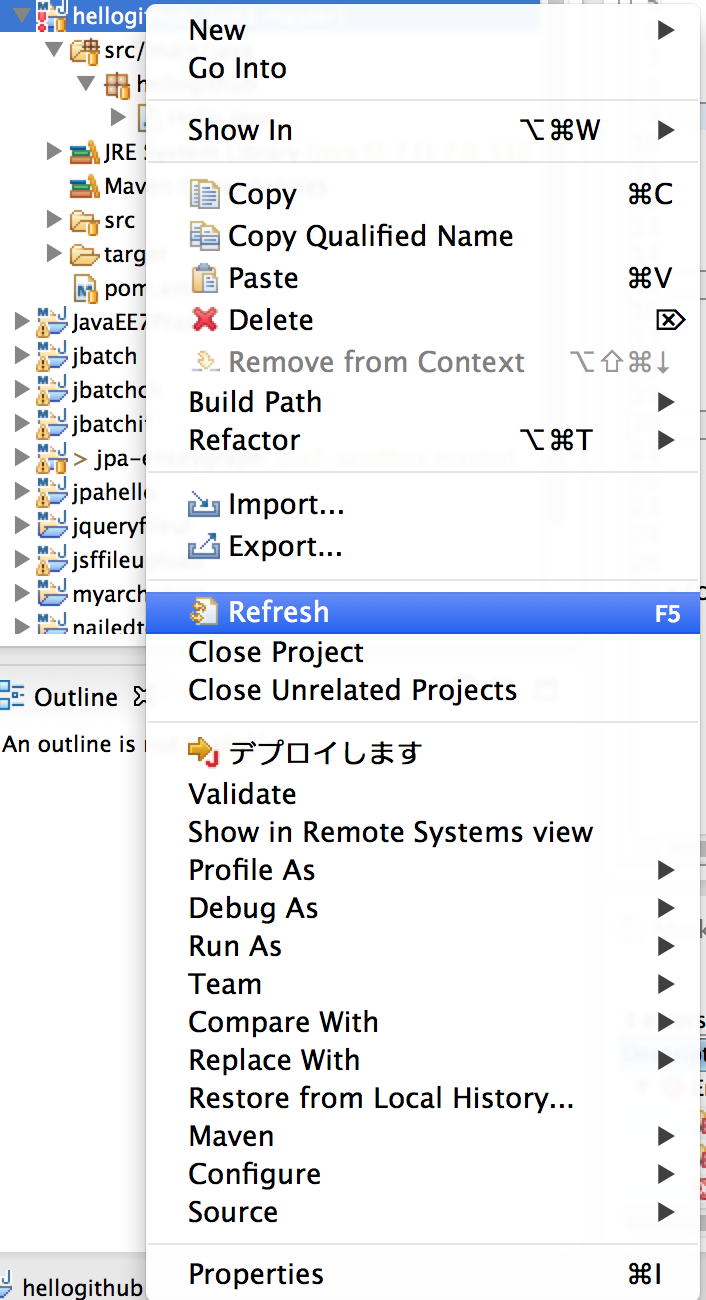
エラーが消える 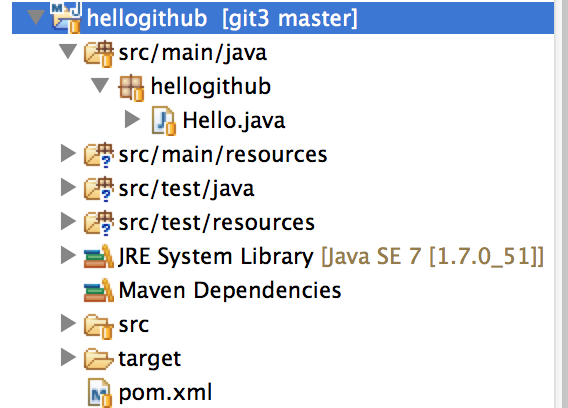
編集→Commit and Pushしてみる
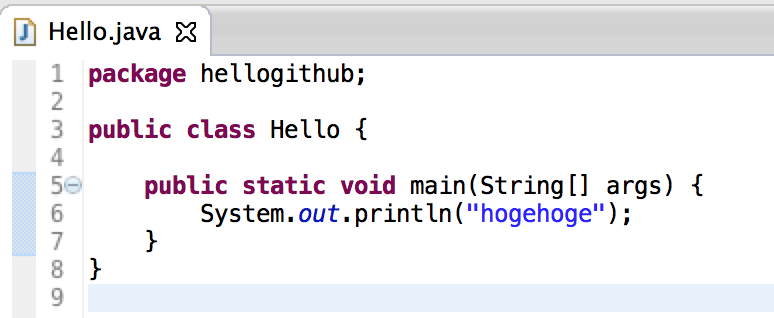
編集する。hogeを追加
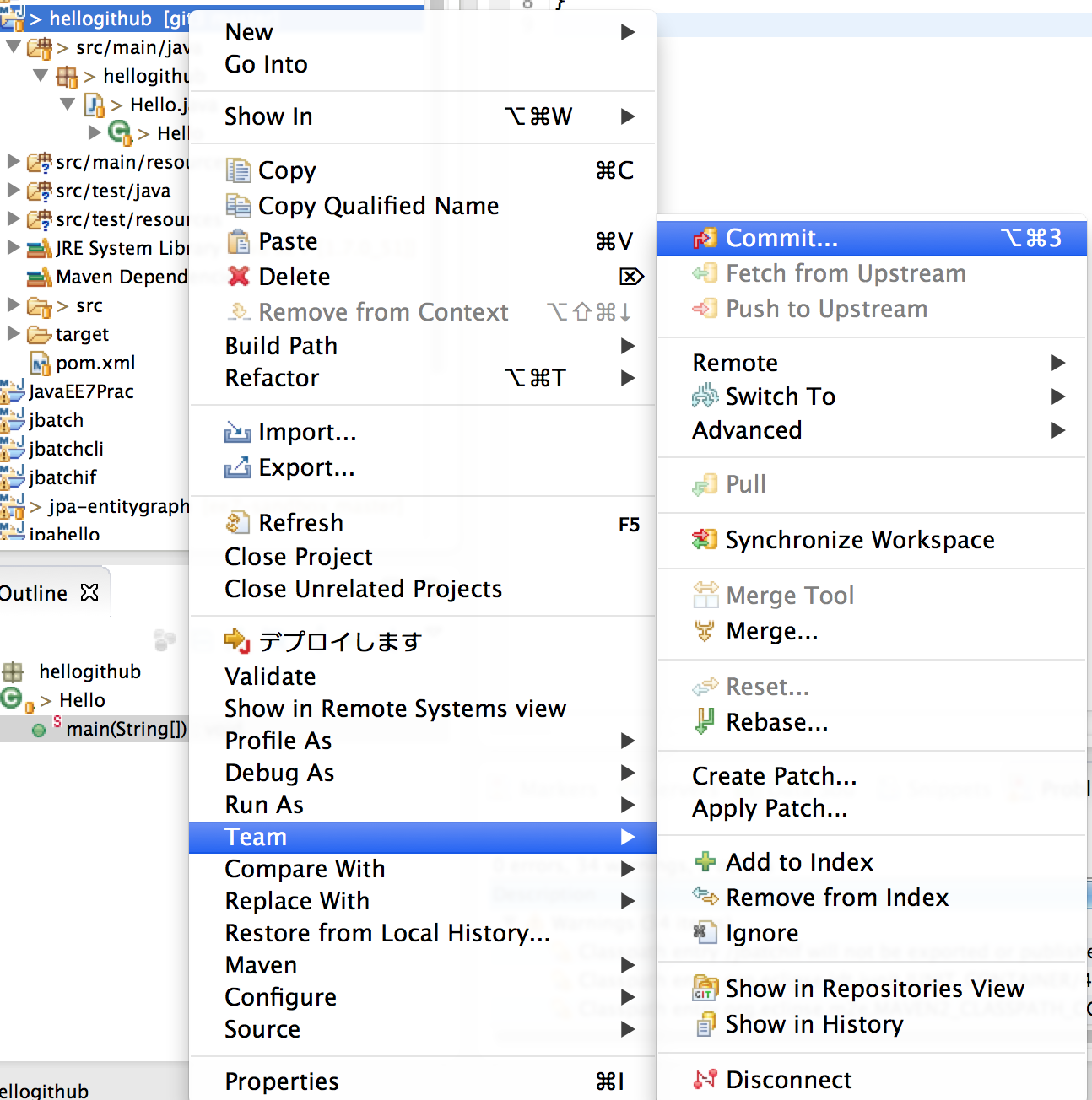
プロジェクトを右クリック→Team→Commit
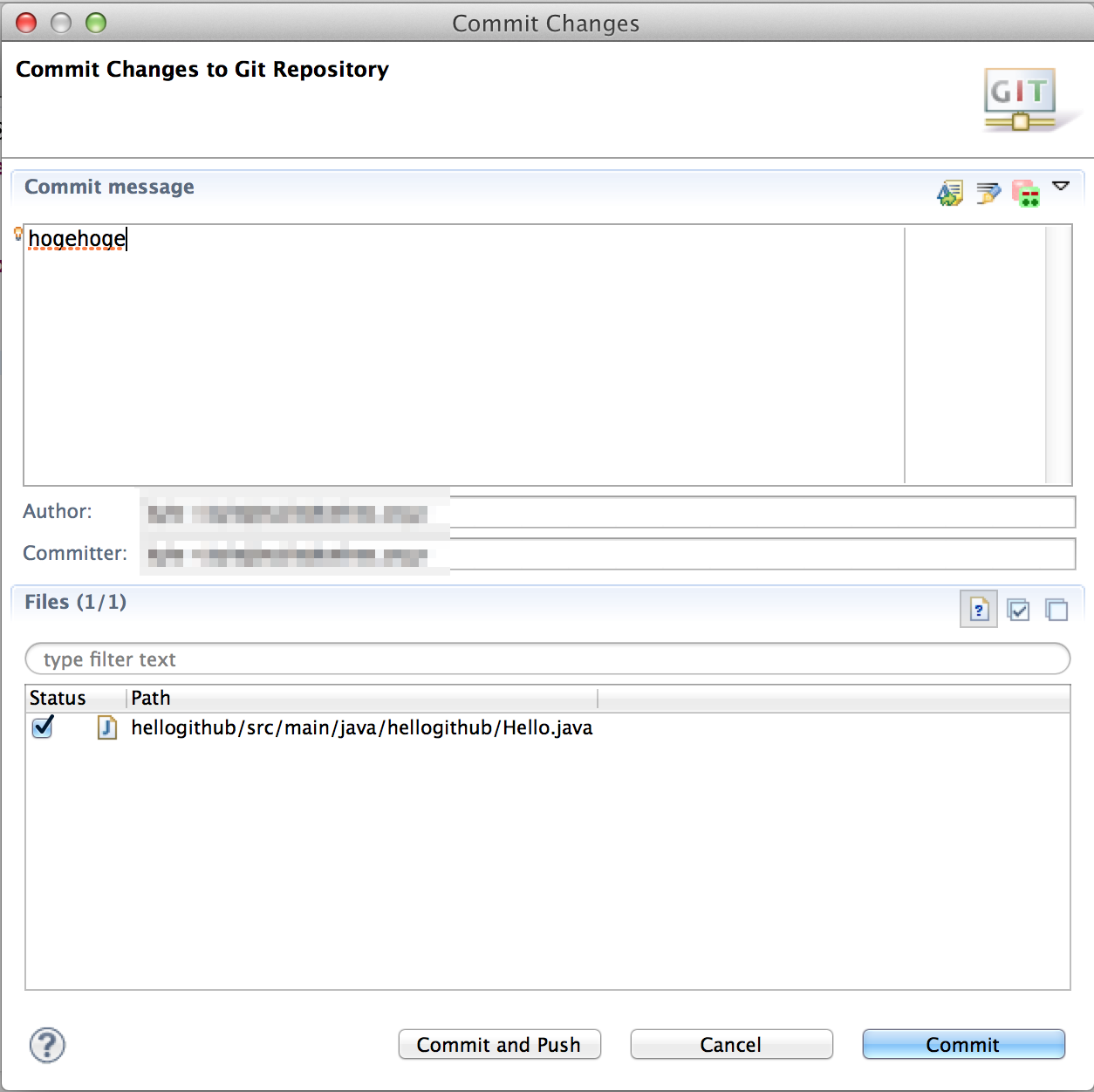
コミットメッセージ入れてCommit and Push
OK
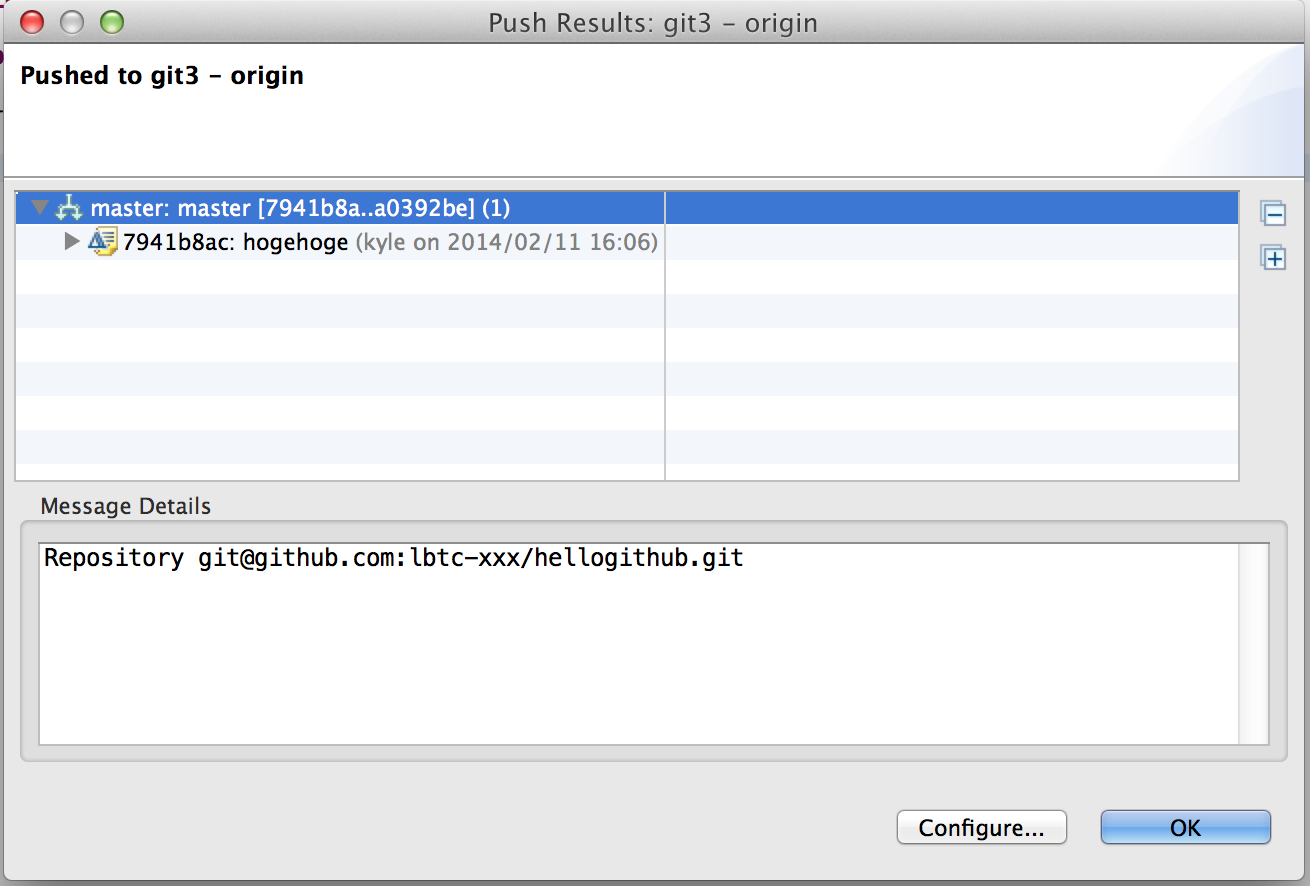
GitHubの画面で編集内容を確認
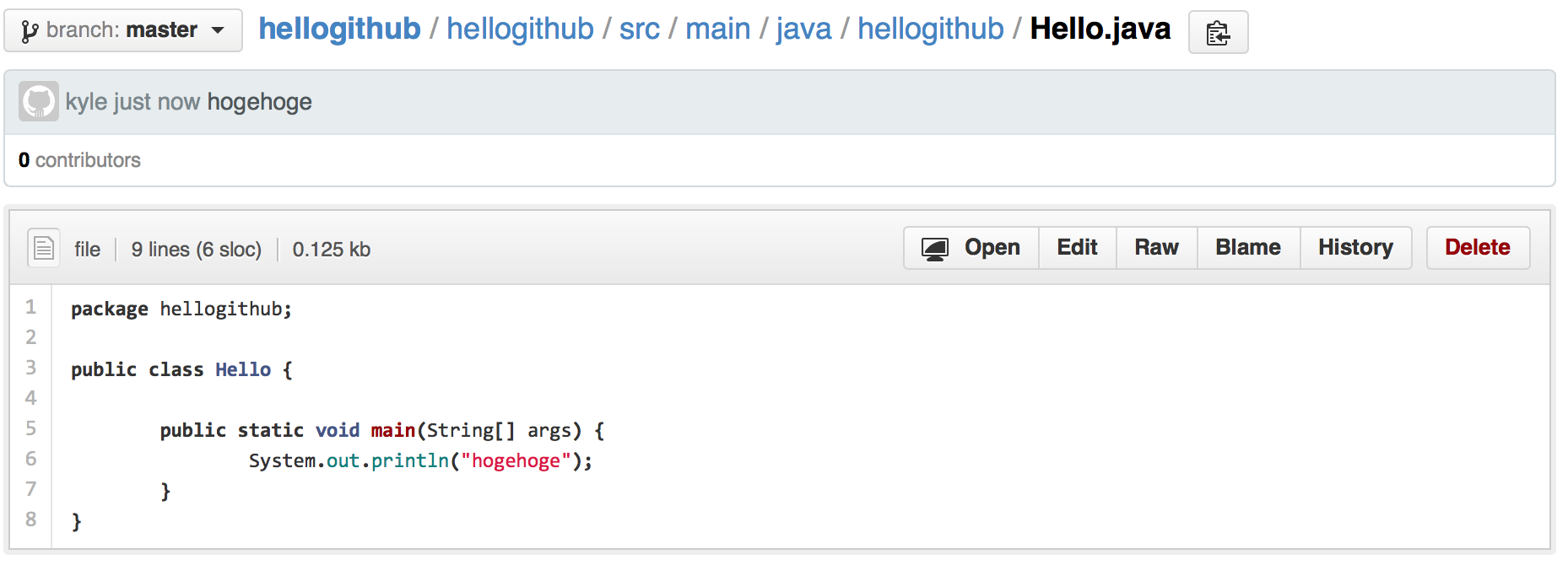
参考文献
Tags: eclipse
GitHubで遊ぶ
TweetPosted on Tuesday Feb 11, 2014 at 11:16AM in Technology
環境
- git version 1.8.3.4 (Apple Git-47)
- OS X 10.9.1
前提条件
GitHubのアカウント登録とssh公開鍵登録は終わっているものとする。
参考文献を見ると専用の鍵ペア作ったりしてたけど面倒なので適当なid_rsa.pubを放り込んどいた。
Repositoryを作る
[2]に書いてあるけど
ホーム画面でNew Repositoryを押す
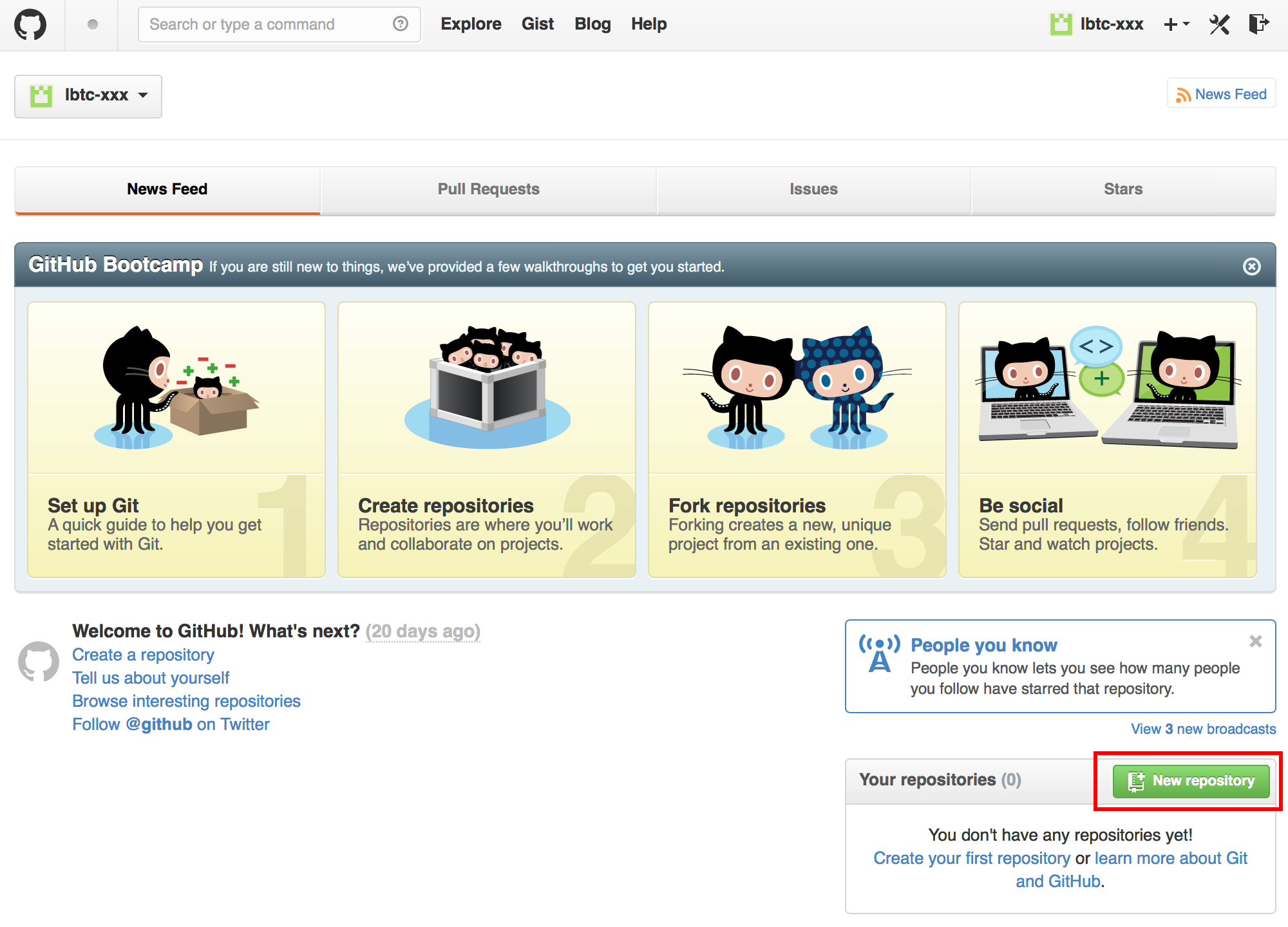
Repository nameとDescriptionを適当に埋めてCreate repositoryを押す
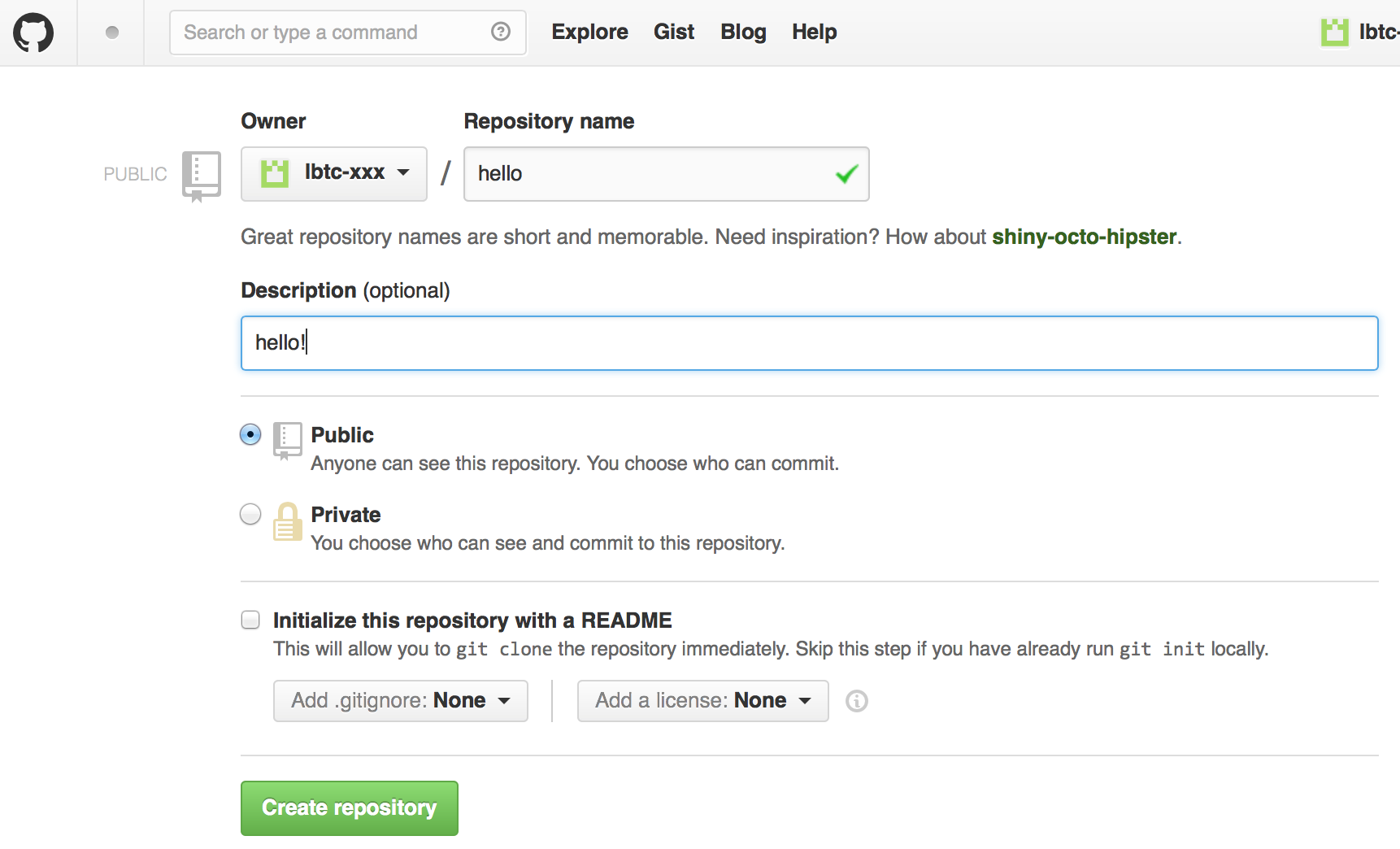
つくられた
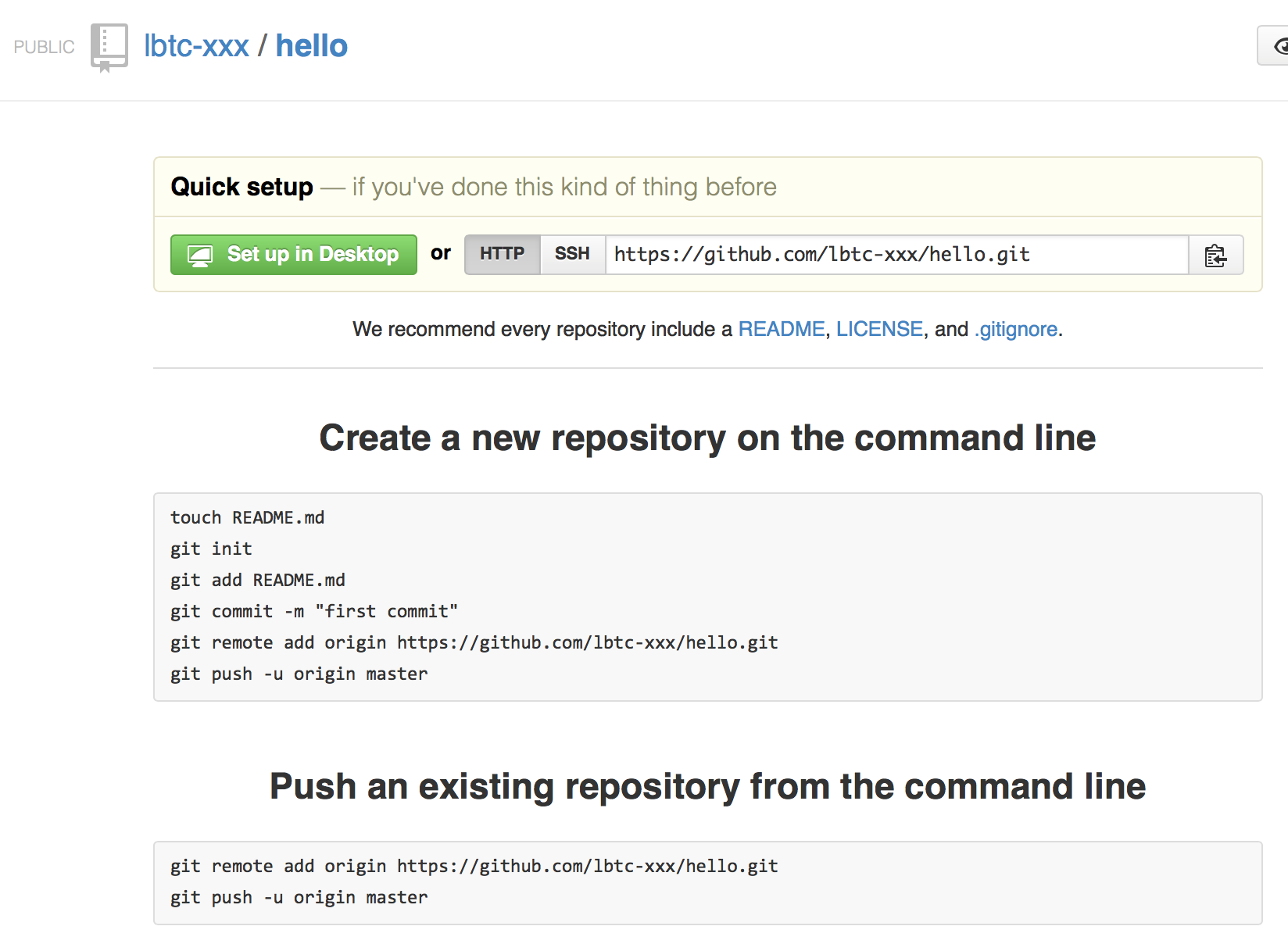
CLIからいじってみる
cloneしてみる
kyle-no-MacBook:gitprac2 kyle$ git clone git@github.com:lbtc-xxx/hello.git Cloning into 'hello'... Warning: Permanently added the RSA host key for IP address '192.30.252.129' to the list of known hosts. warning: You appear to have cloned an empty repository. Checking connectivity... done kyle-no-MacBook:gitprac2 kyle$ ls -ld hello drwxr-xr-x+ 3 kyle staff 102 2 11 11:28 hello kyle-no-MacBook:gitprac2 kyle$ ls -lR hello total 80 -rwxr-xr-x+ 1 kyle staff 452 2 11 11:28 applypatch-msg.sample -rwxr-xr-x+ 1 kyle staff 896 2 11 11:28 commit-msg.sample -rwxr-xr-x+ 1 kyle staff 189 2 11 11:28 post-update.sample -rwxr-xr-x+ 1 kyle staff 398 2 11 11:28 pre-applypatch.sample -rwxr-xr-x+ 1 kyle staff 1704 2 11 11:28 pre-commit.sample -rwxr-xr-x+ 1 kyle staff 1348 2 11 11:28 pre-push.sample -rwxr-xr-x+ 1 kyle staff 4951 2 11 11:28 pre-rebase.sample -rwxr-xr-x+ 1 kyle staff 1239 2 11 11:28 prepare-commit-msg.sample -rwxr-xr-x+ 1 kyle staff 3611 2 11 11:28 update.sample hello/.git/info: total 8 -rw-r--r--+ 1 kyle staff 240 2 11 11:28 exclude hello/.git/objects: total 0 drwxr-xr-x+ 2 kyle staff 68 2 11 11:28 info drwxr-xr-x+ 2 kyle staff 68 2 11 11:28 pack hello/.git/objects/info: hello/.git/objects/pack: hello/.git/refs: total 0 drwxr-xr-x+ 2 kyle staff 68 2 11 11:28 heads drwxr-xr-x+ 2 kyle staff 68 2 11 11:28 tags hello/.git/refs/heads: hello/.git/refs/tags: kyle-no-MacBook:gitprac2 kyle$ %%%
よくわからないけど何かgitのディレクトリ構造っぽいものができている。
commitしてみる
kyle-no-MacBook:gitprac2 kyle$ cd hello kyle-no-MacBook:hello kyle$ echo hoge > README.md kyle-no-MacBook:hello kyle$ git add README.md kyle-no-MacBook:hello kyle$ git commit -m "first commit" [master (root-commit) 30ec784] first commit 1 file changed, 1 insertion(+) create mode 100644 README.md kyle-no-MacBook:hello kyle$
この時点ではGitHub側の画面をリロードしても資源が上がったりはしていない。たぶんpushってのをやらないとだめなんだろう。
pushしてみる
kyle-no-MacBook:hello kyle$ git push warning: push.default is unset; its implicit value is changing in Git 2.0 from 'matching' to 'simple'. To squelch this message and maintain the current behavior after the default changes, use: git config --global push.default matching To squelch this message and adopt the new behavior now, use: git config --global push.default simple See 'git help config' and search for 'push.default' for further information. (the 'simple' mode was introduced in Git 1.7.11. Use the similar mode 'current' instead of 'simple' if you sometimes use older versions of Git) Warning: Permanently added the RSA host key for IP address '192.30.252.130' to the list of known hosts. No refs in common and none specified; doing nothing. Perhaps you should specify a branch such as 'master'. fatal: The remote end hung up unexpectedly error: failed to push some refs to 'git@github.com:lbtc-xxx/hello.git' kyle-no-MacBook:hello kyle$
よくわからないけどおこられた。[4]を見ると何やらパラメータが必要っぽいのでよくわからないけど追加してみる
kyle-no-MacBook:hello kyle$ git push origin master Counting objects: 3, done. Writing objects: 100% (3/3), 214 bytes | 0 bytes/s, done. Total 3 (delta 0), reused 0 (delta 0) To git@github.com:lbtc-xxx/hello.git * [new branch] master -> master kyle-no-MacBook:hello kyle$
GitHubのgitのコマンド例が書かれたページをリロードしてみると 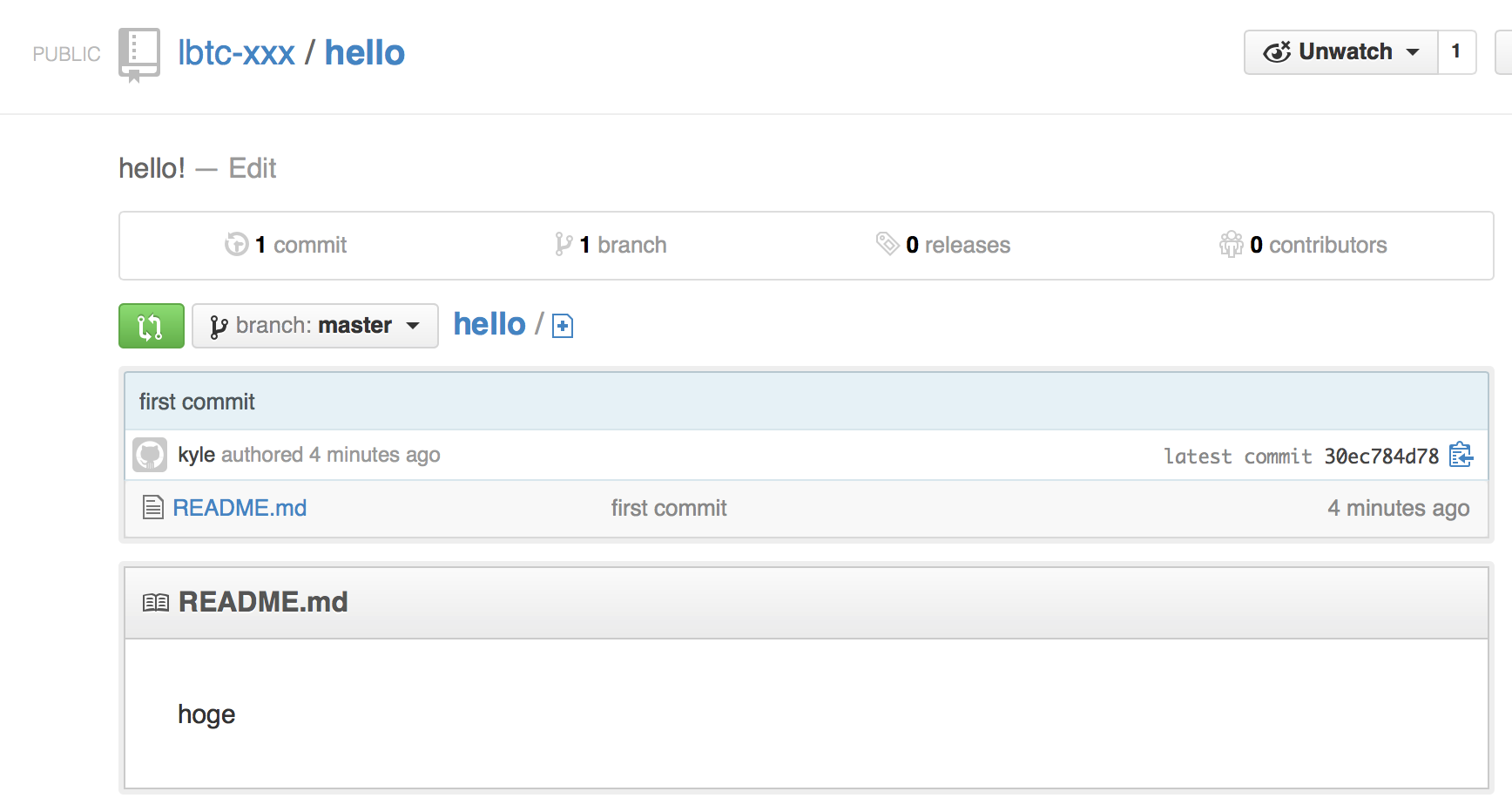
何かがアップロードされた。うむ
編集してadd→commit→pushしてみる
kyle-no-MacBook:hello kyle$ echo hogehoge >> README.md kyle-no-MacBook:hello kyle$ git add README.md kyle-no-MacBook:hello kyle$ git commit -m "second commit" [master 79e339f] second commit 1 file changed, 1 insertion(+) kyle-no-MacBook:hello kyle$ git push origin master Counting objects: 5, done. Writing objects: 100% (3/3), 249 bytes | 0 bytes/s, done. Total 3 (delta 0), reused 0 (delta 0) To git@github.com:lbtc-xxx/hello.git 30ec784..79e339f master -> master kyle-no-MacBook:hello kyle$
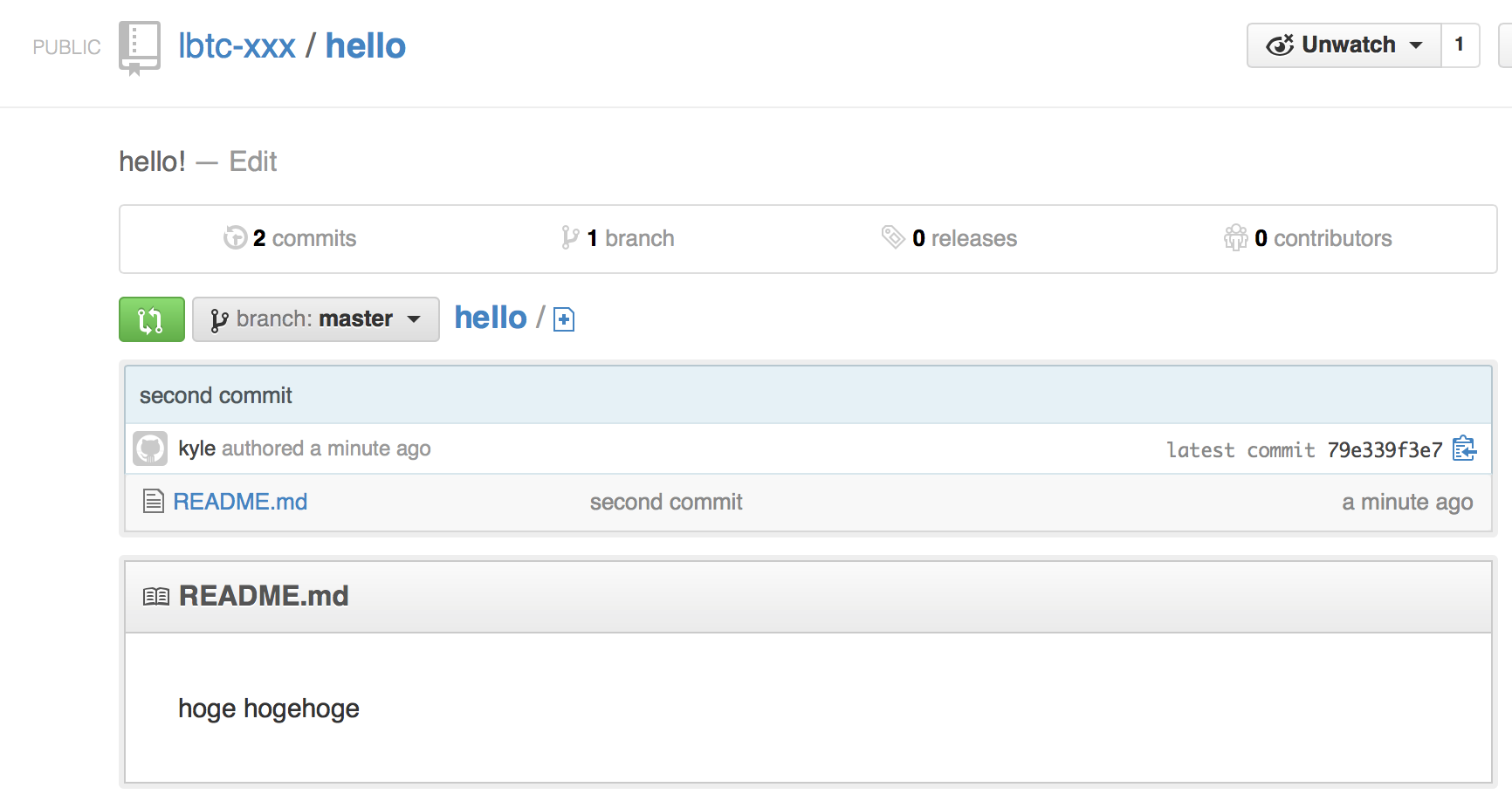
うむ。
参考文献
Tags: git
GitHubにプロジェクトを上げてみる
TweetPosted on Tuesday Feb 11, 2014 at 10:49AM in Technology
環境
- Eclipse Kelper SR1
- OS X 10.9.1
前提条件
- GitHubのアカウント登録とssh公開鍵登録は終わっているものとする。GitHubで遊ぶでやった感じ。
- ローカルリポジトリへのcommitが出来る状態になっているプロジェクトが存在するものとする。ローカルで一人用Gitを使ってみるでやった感じ。
準備
プロジェクトの確認
GitHubにリポジトリを作る
GitHubで遊ぶでやった感じでGitHubにリポジトリを作る。
Push
Team→Remote→Push
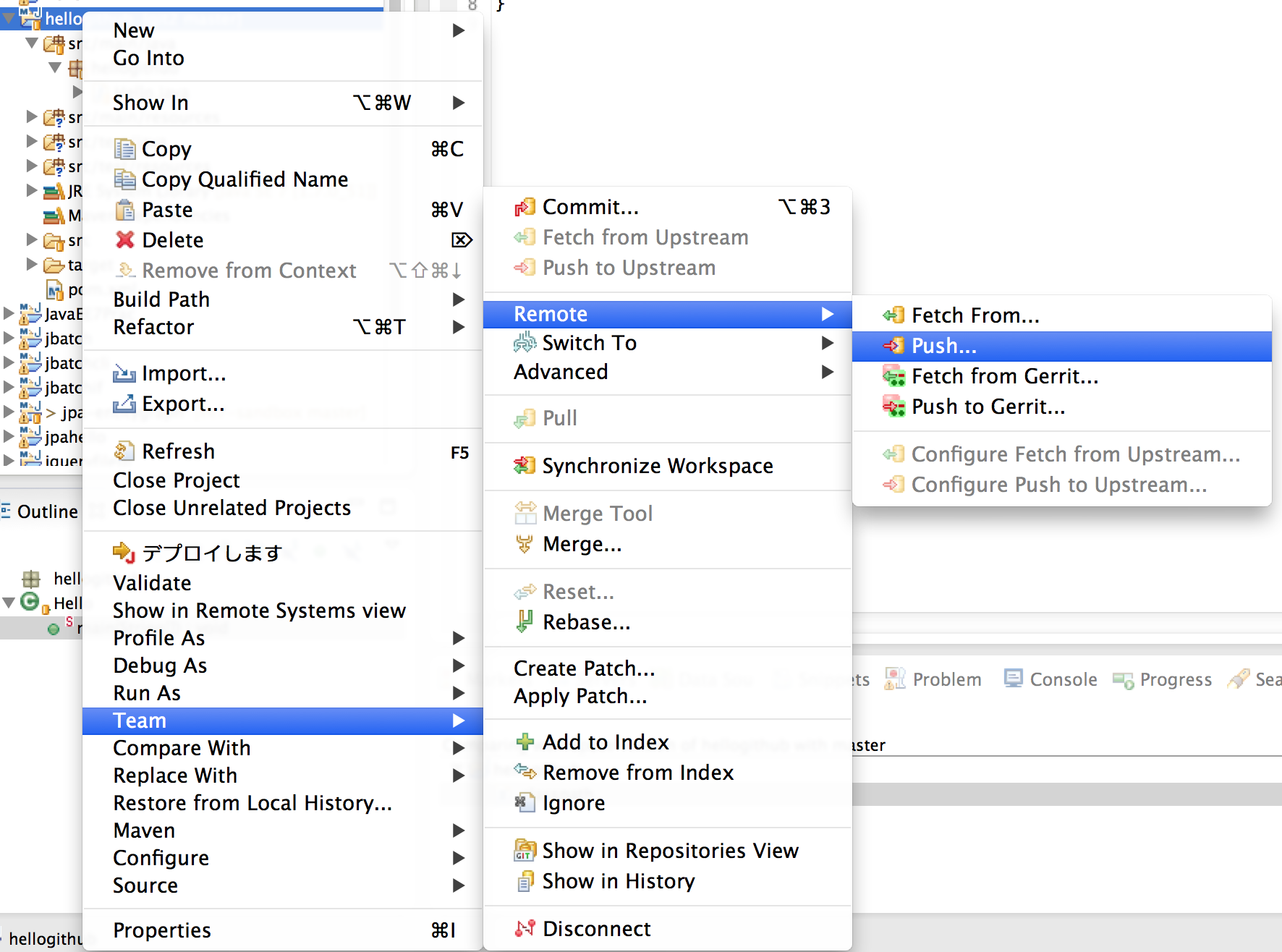
準備で作ったリポジトリのURIをコピーして貼付けてNext
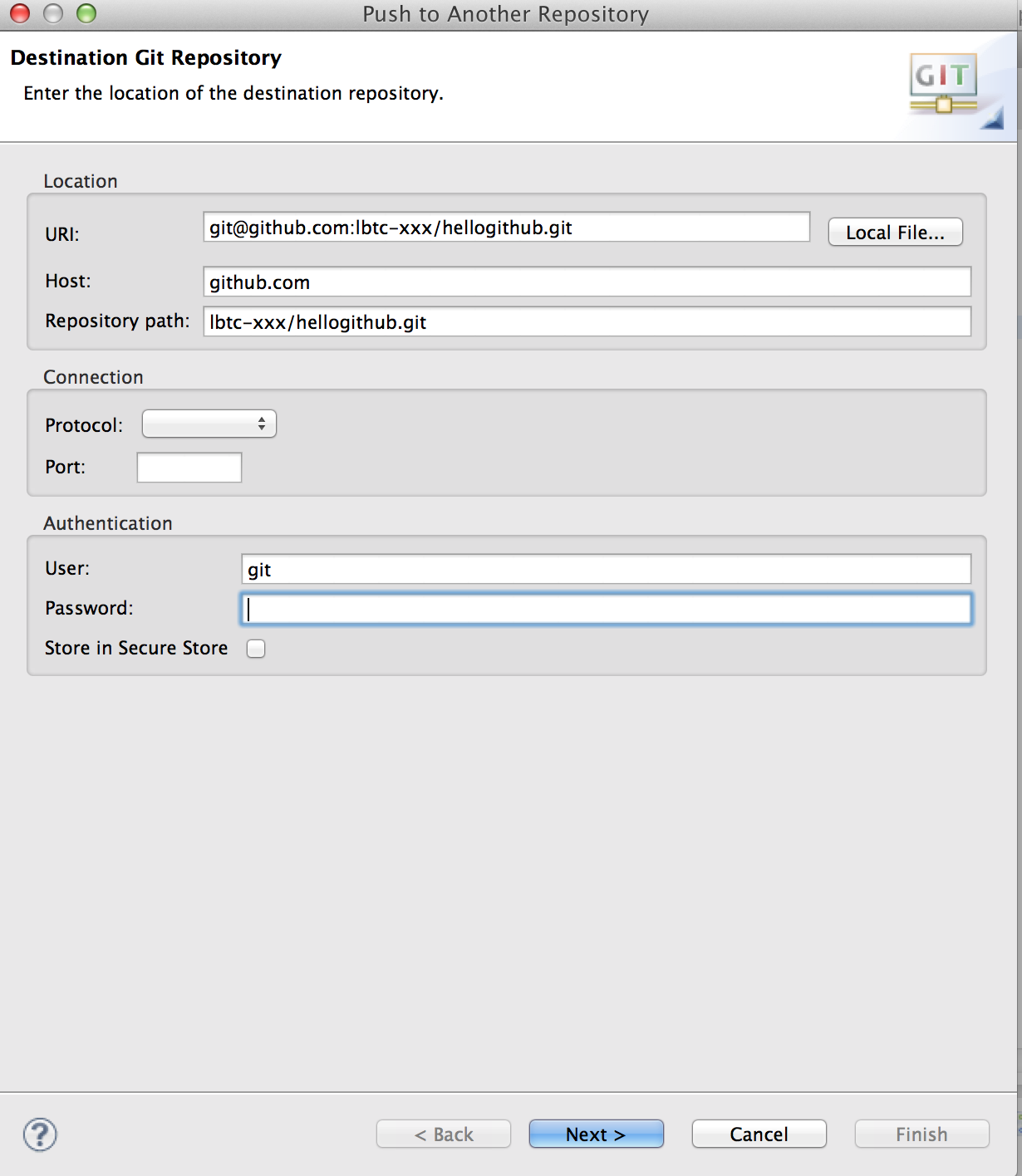
Source refからmaster [branch]を選んでAdd Specを押す
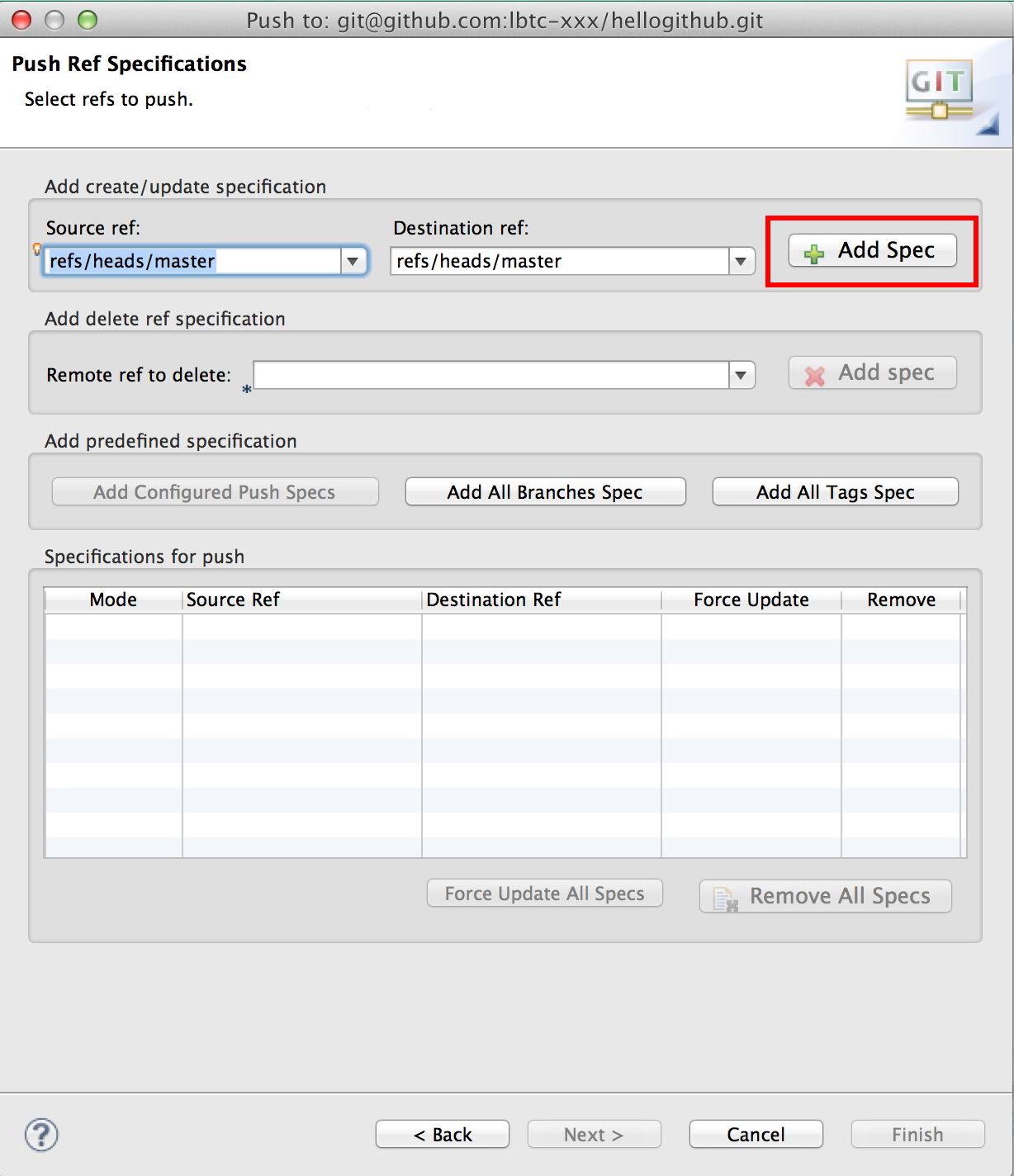
Finish
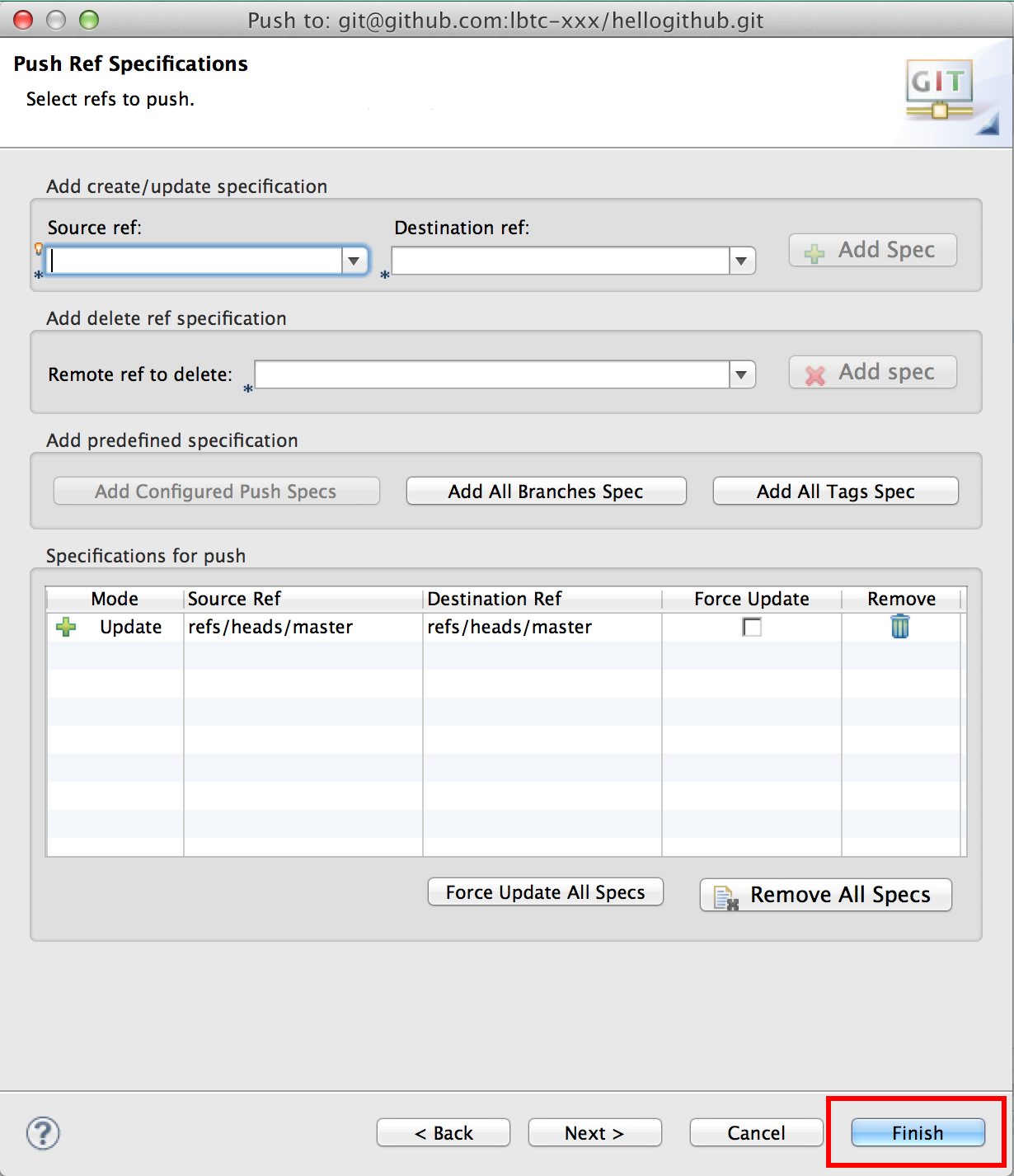
何やら処理が行われてこんなのが表示される
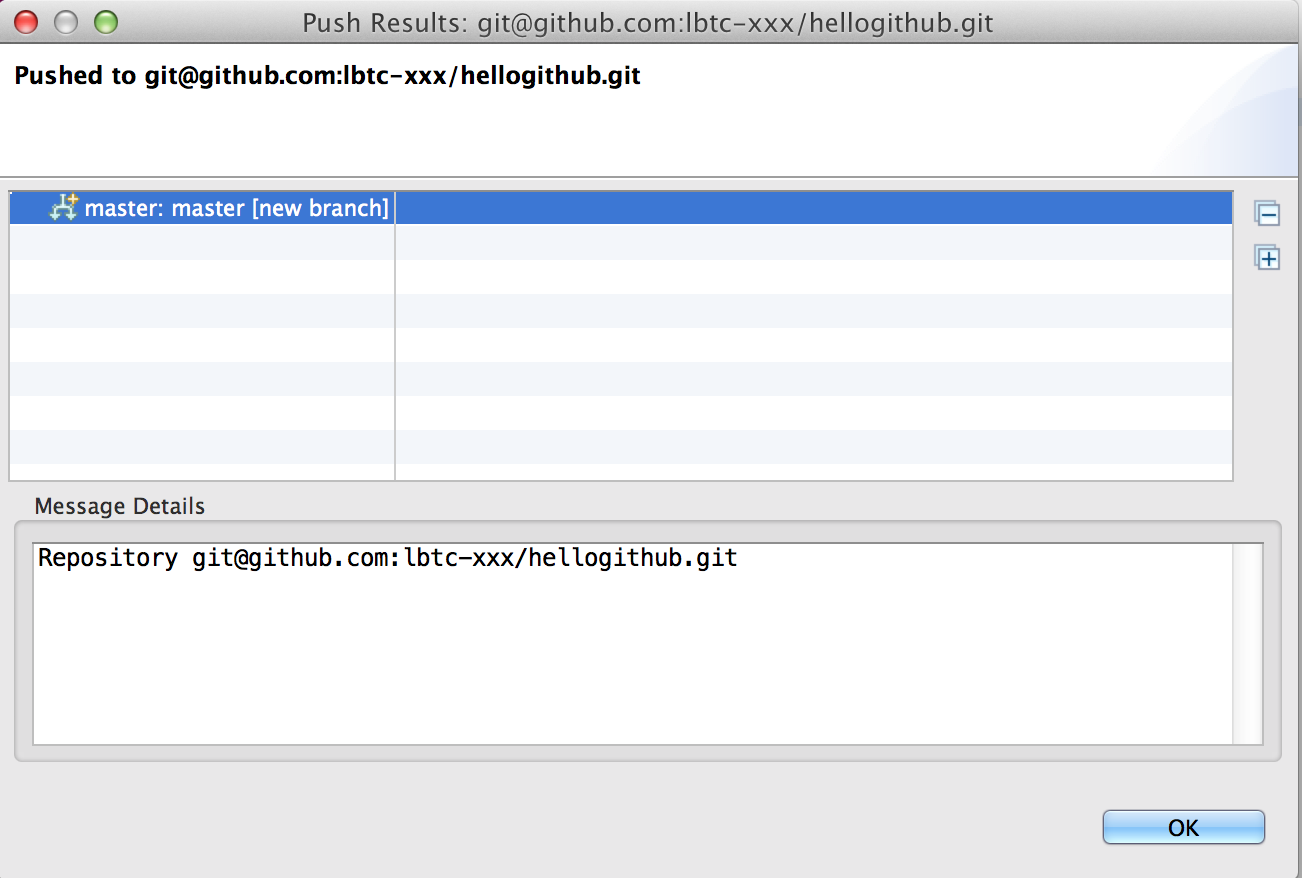
GitHubのリポジトリを確認してみる
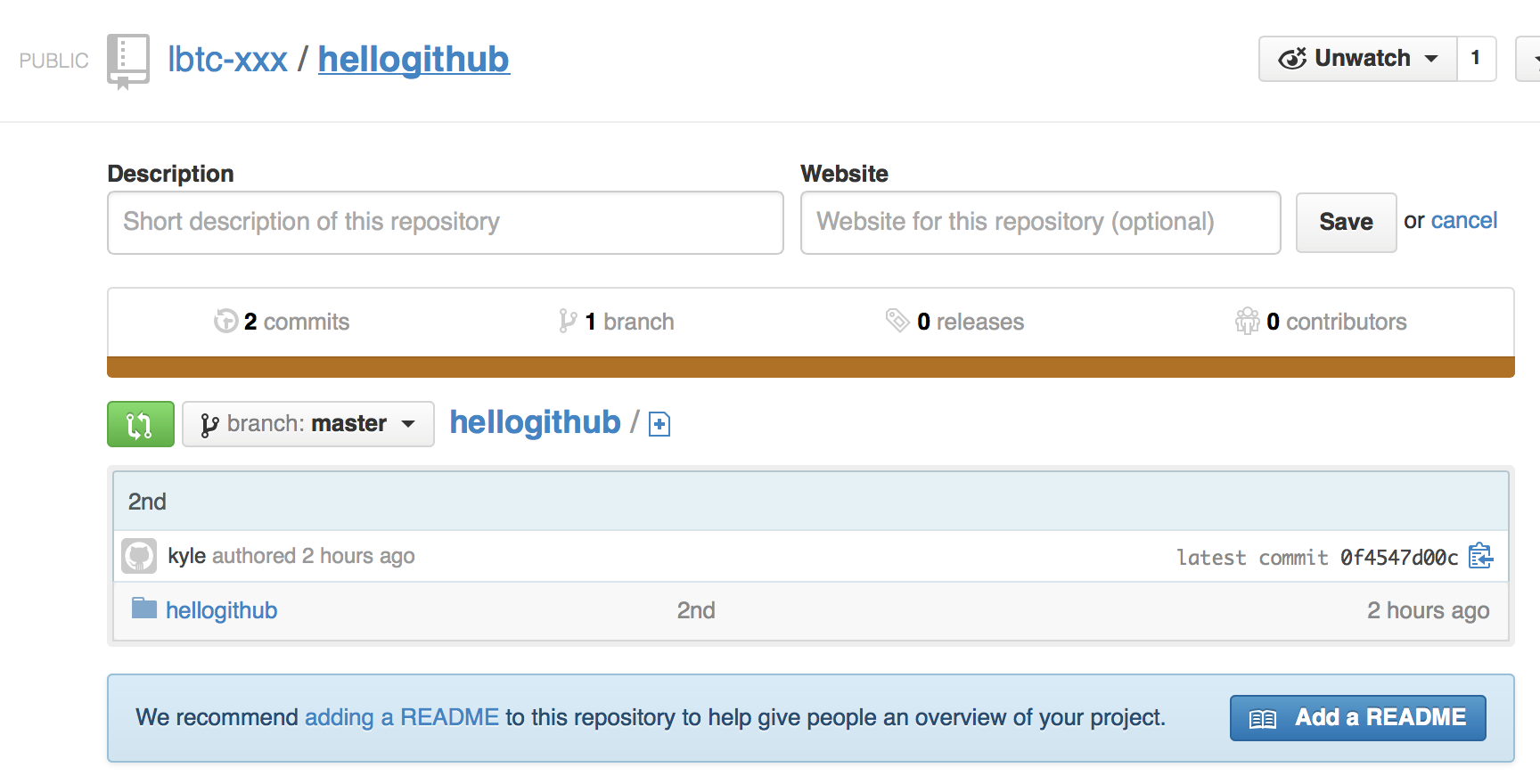
それっぽいのが出来ているようだ
参考文献
Tags: eclipse
